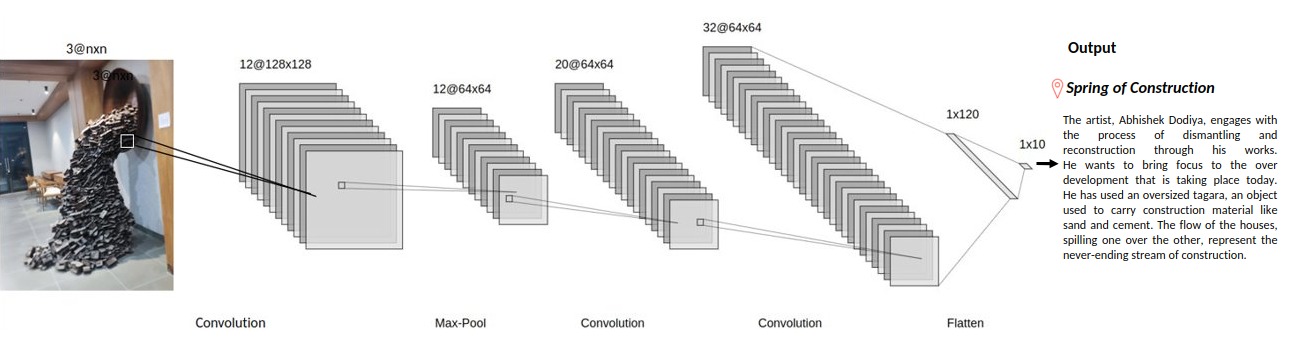
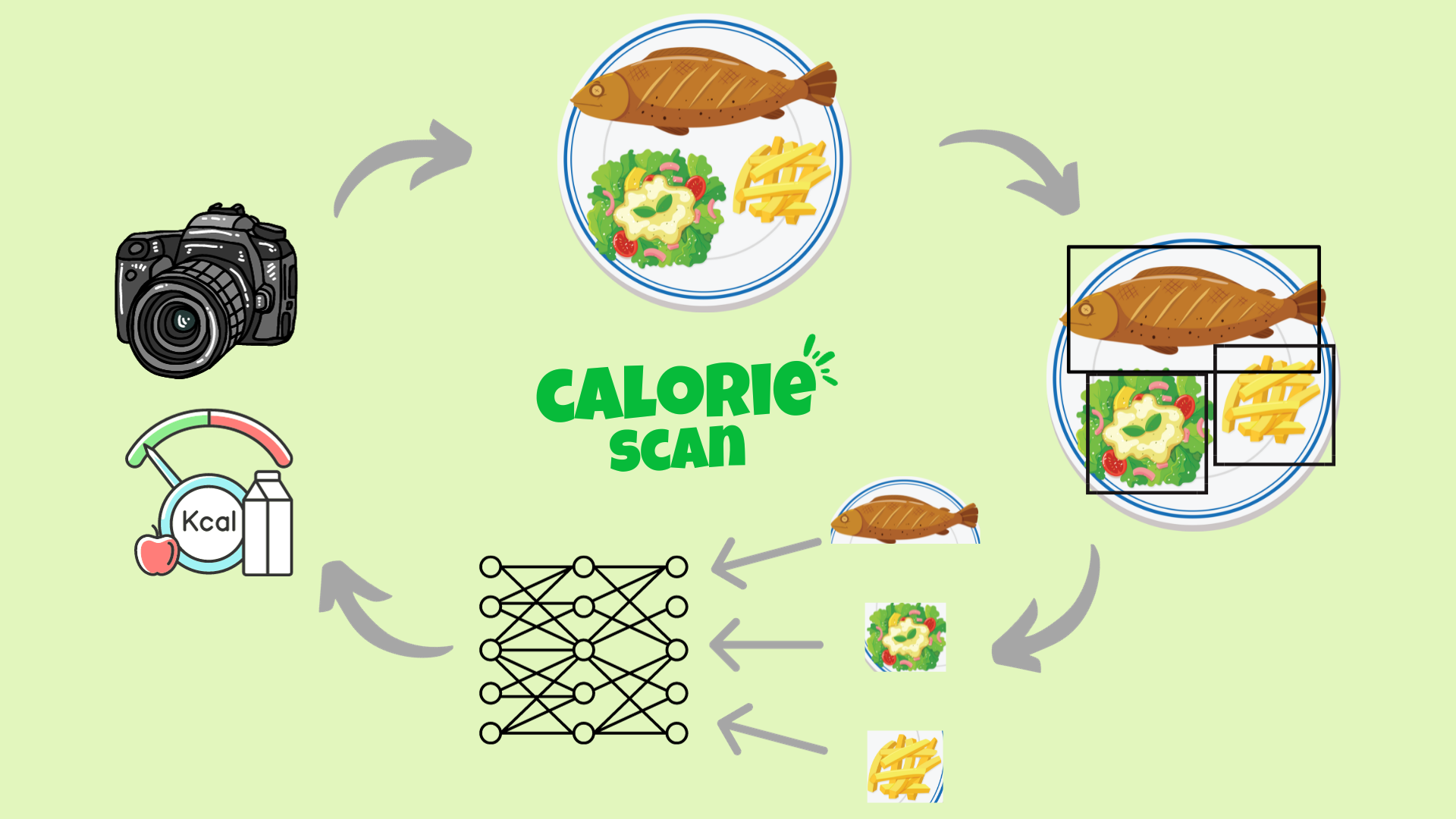
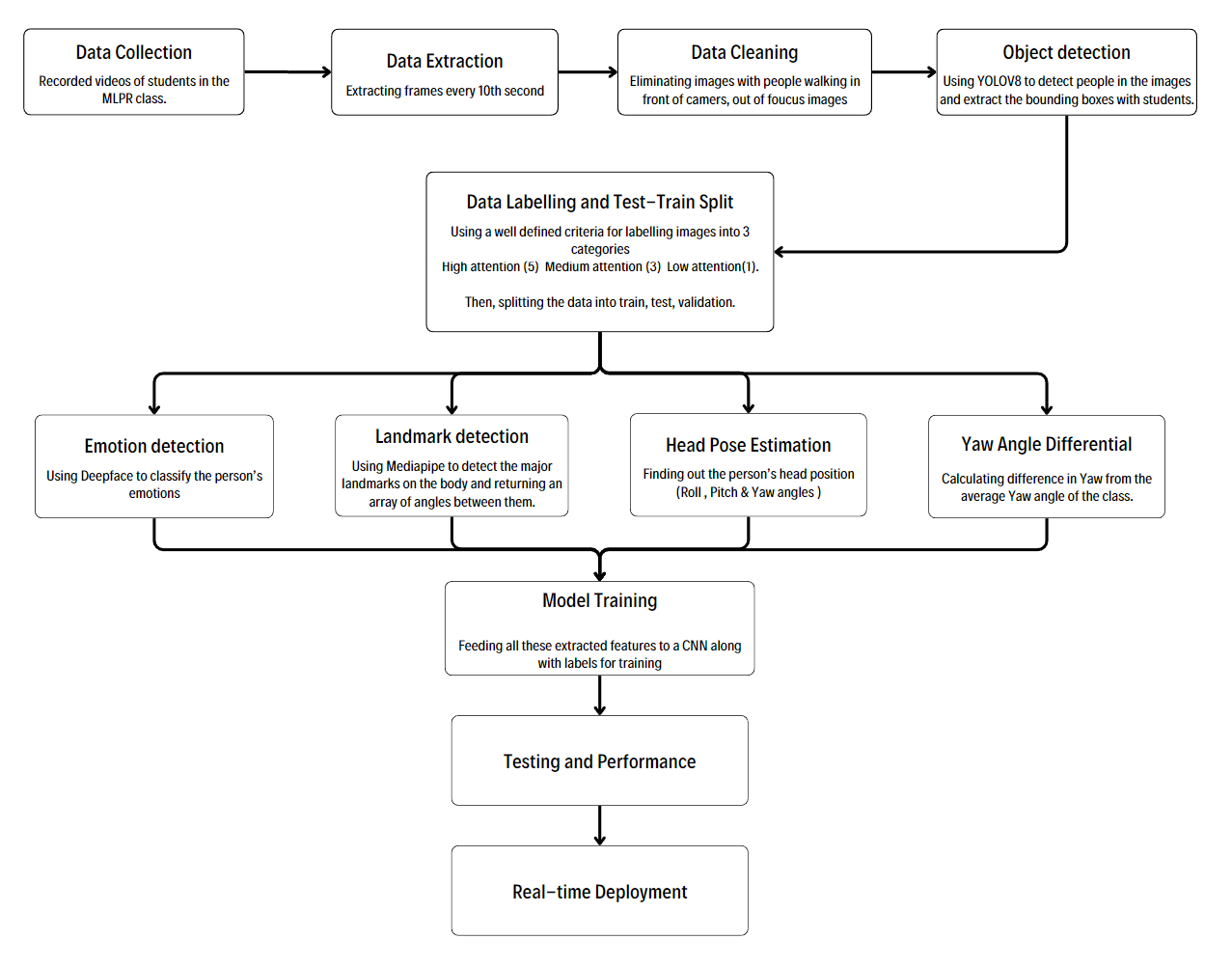
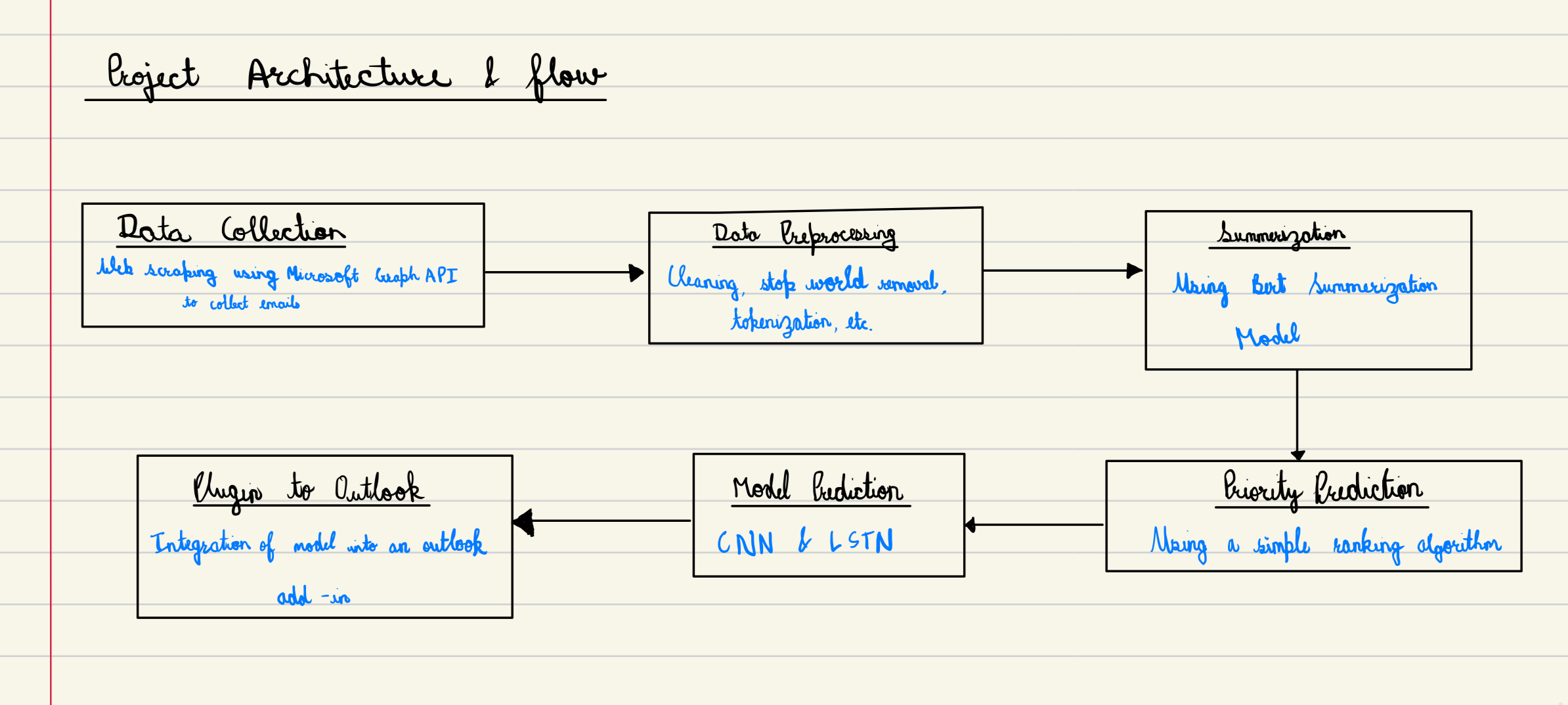
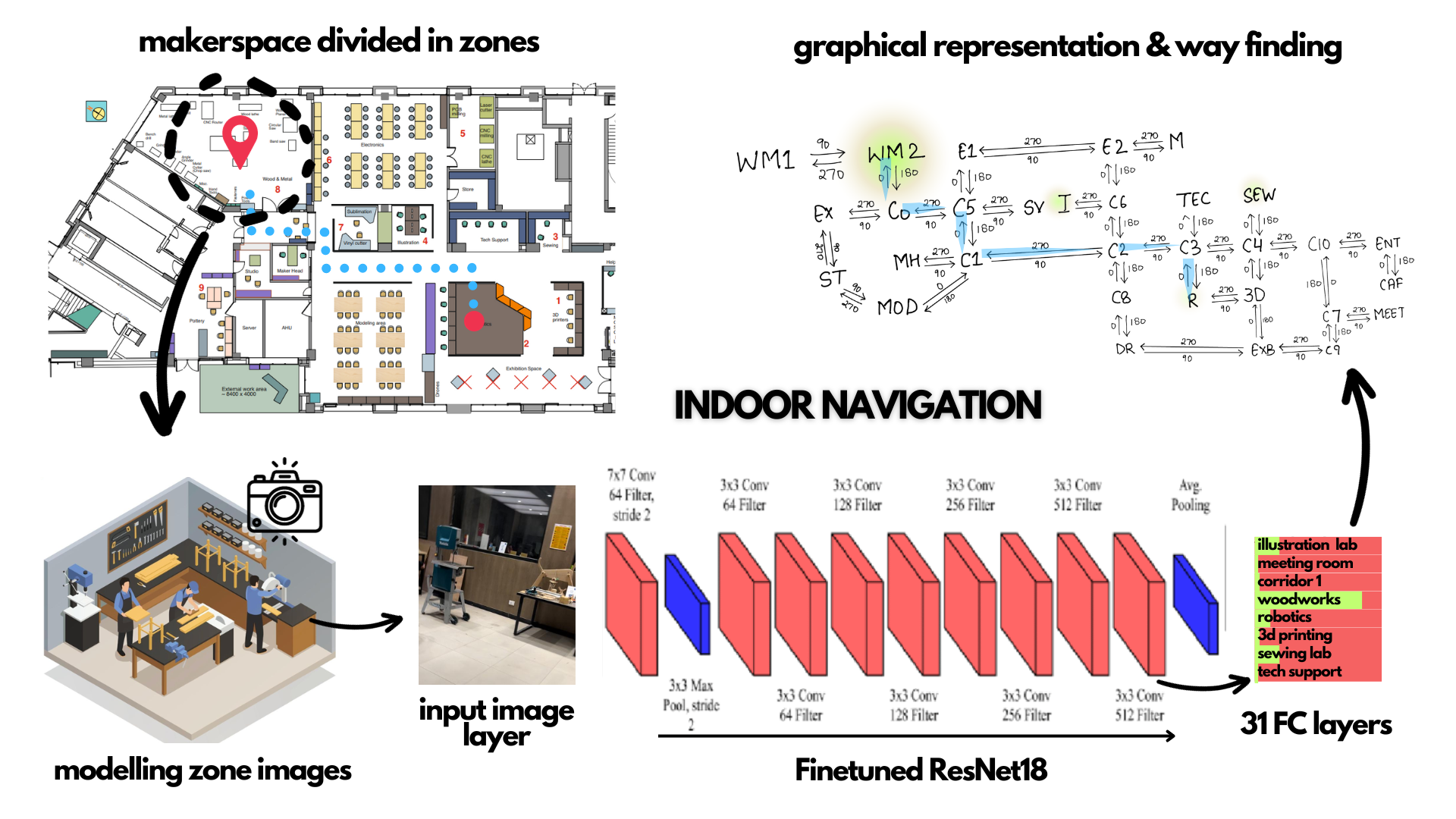
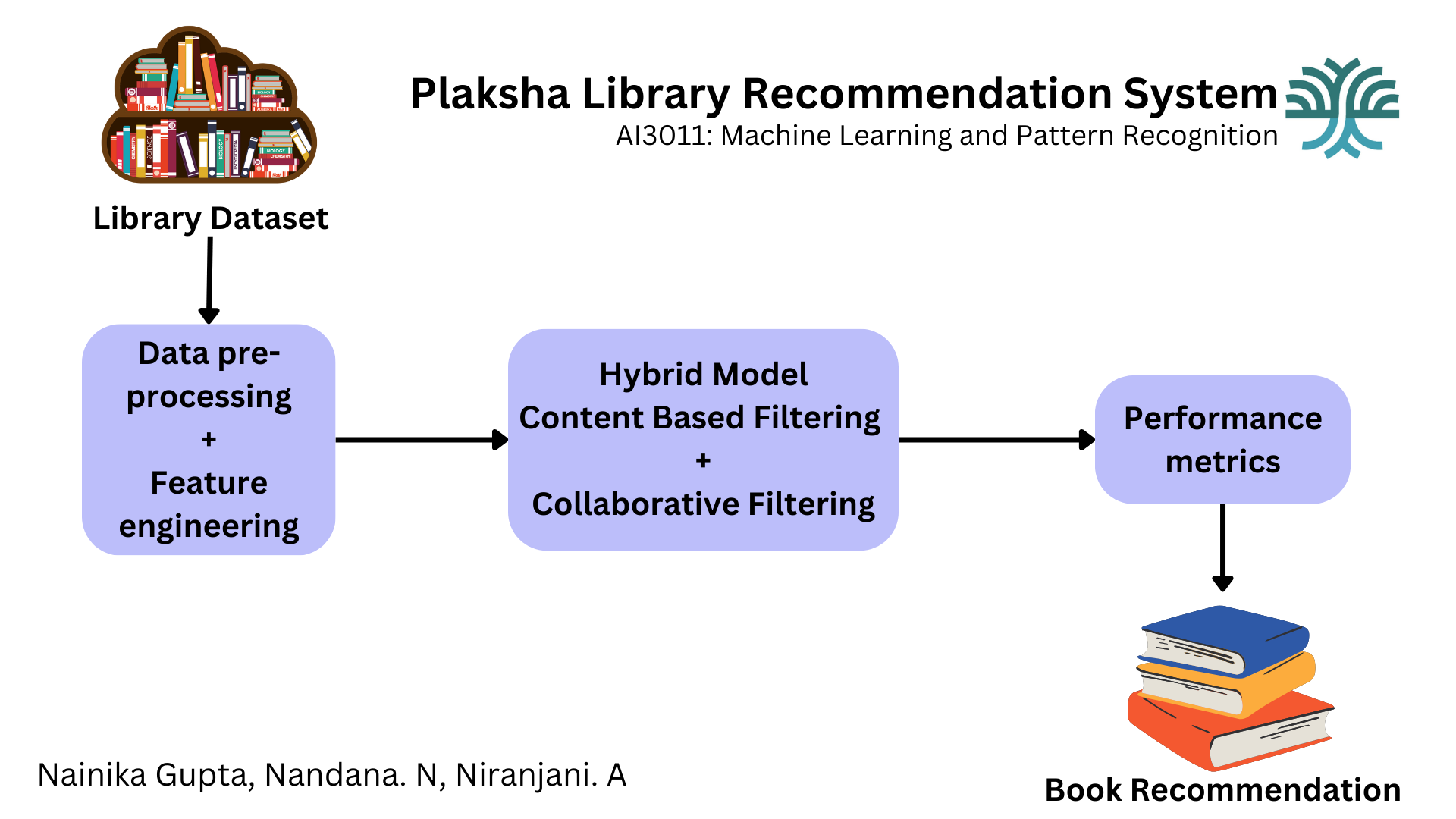
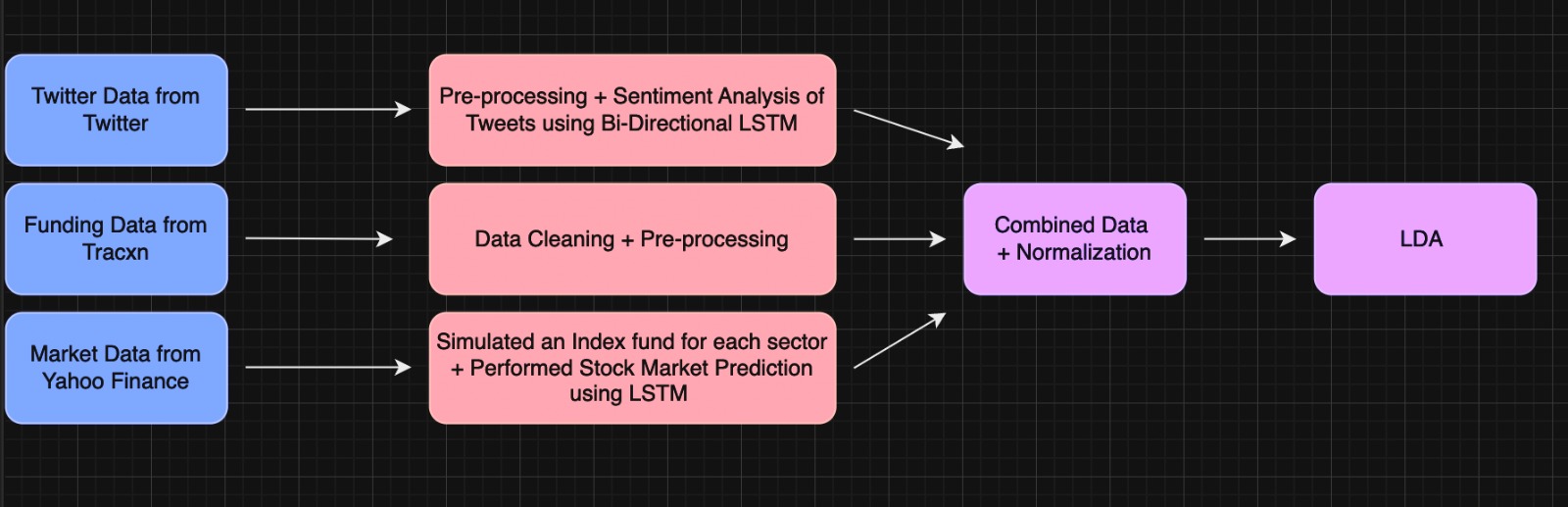
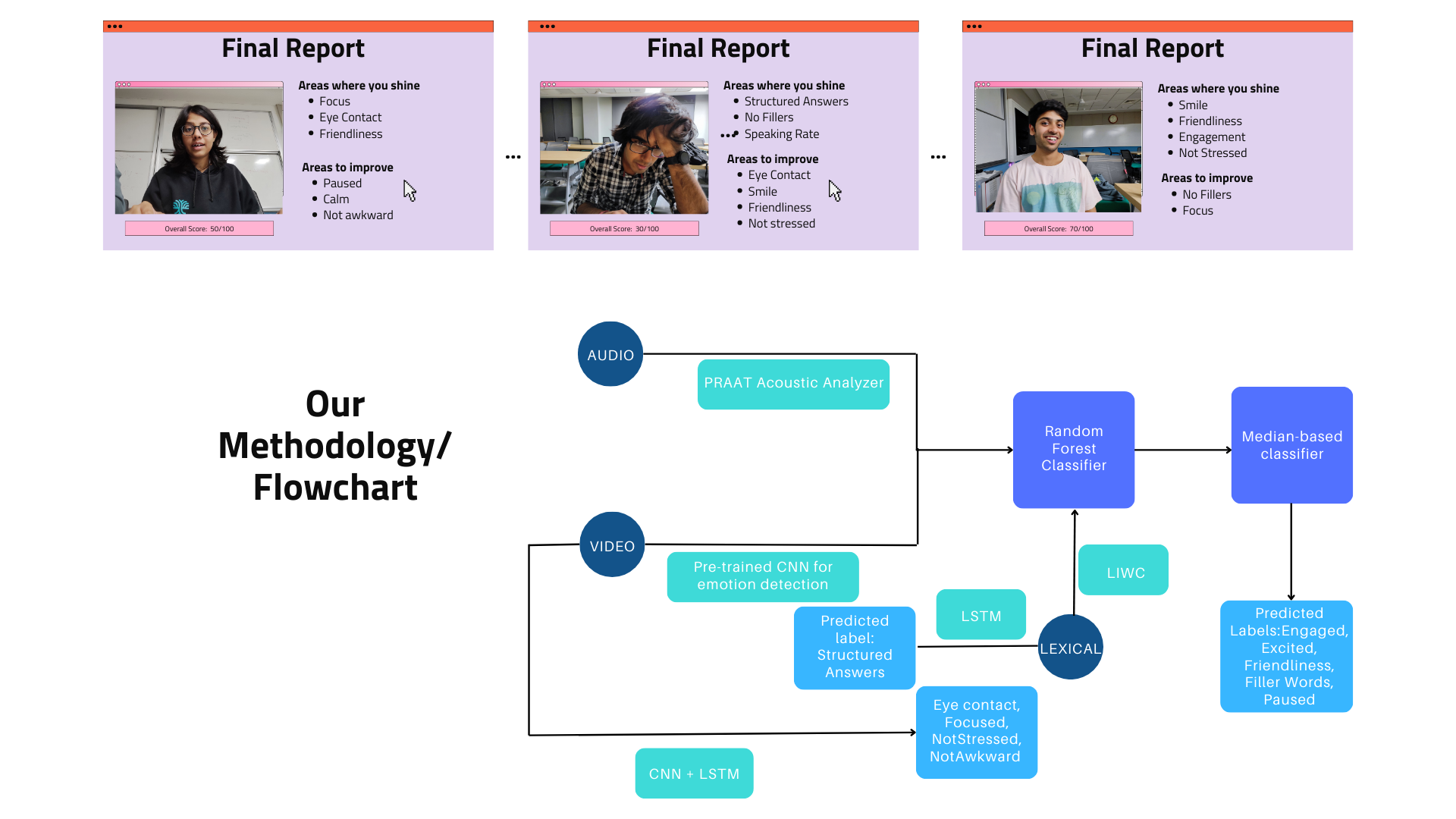
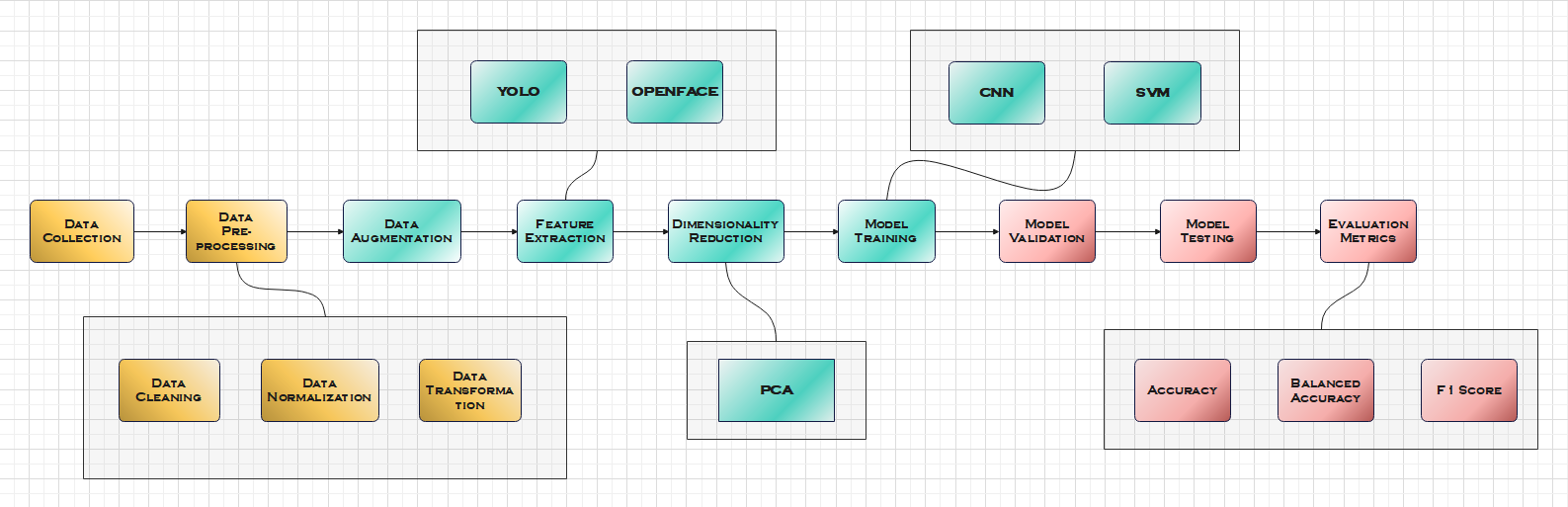
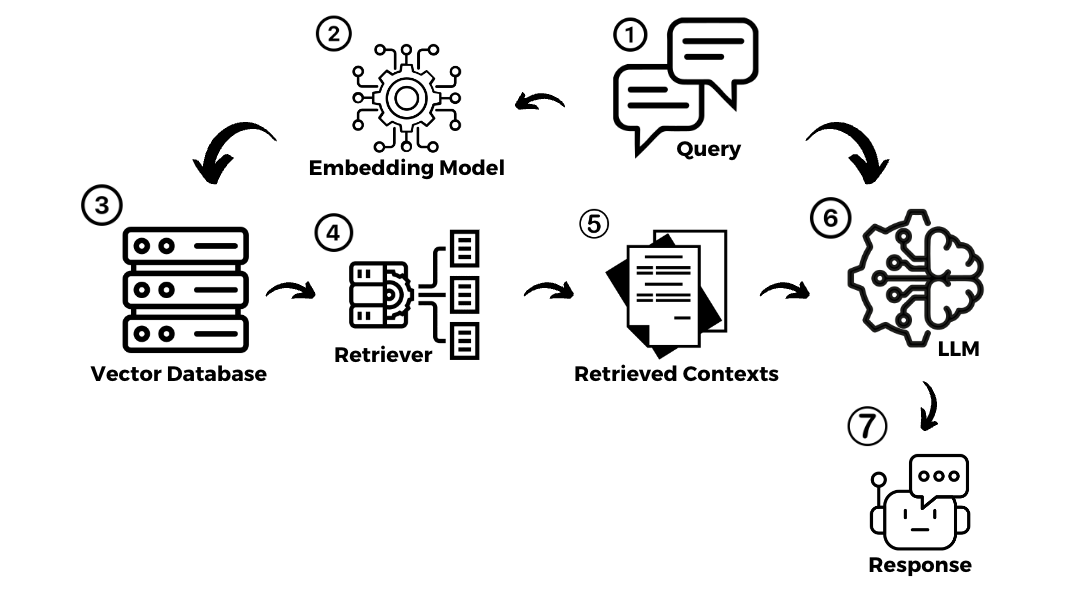
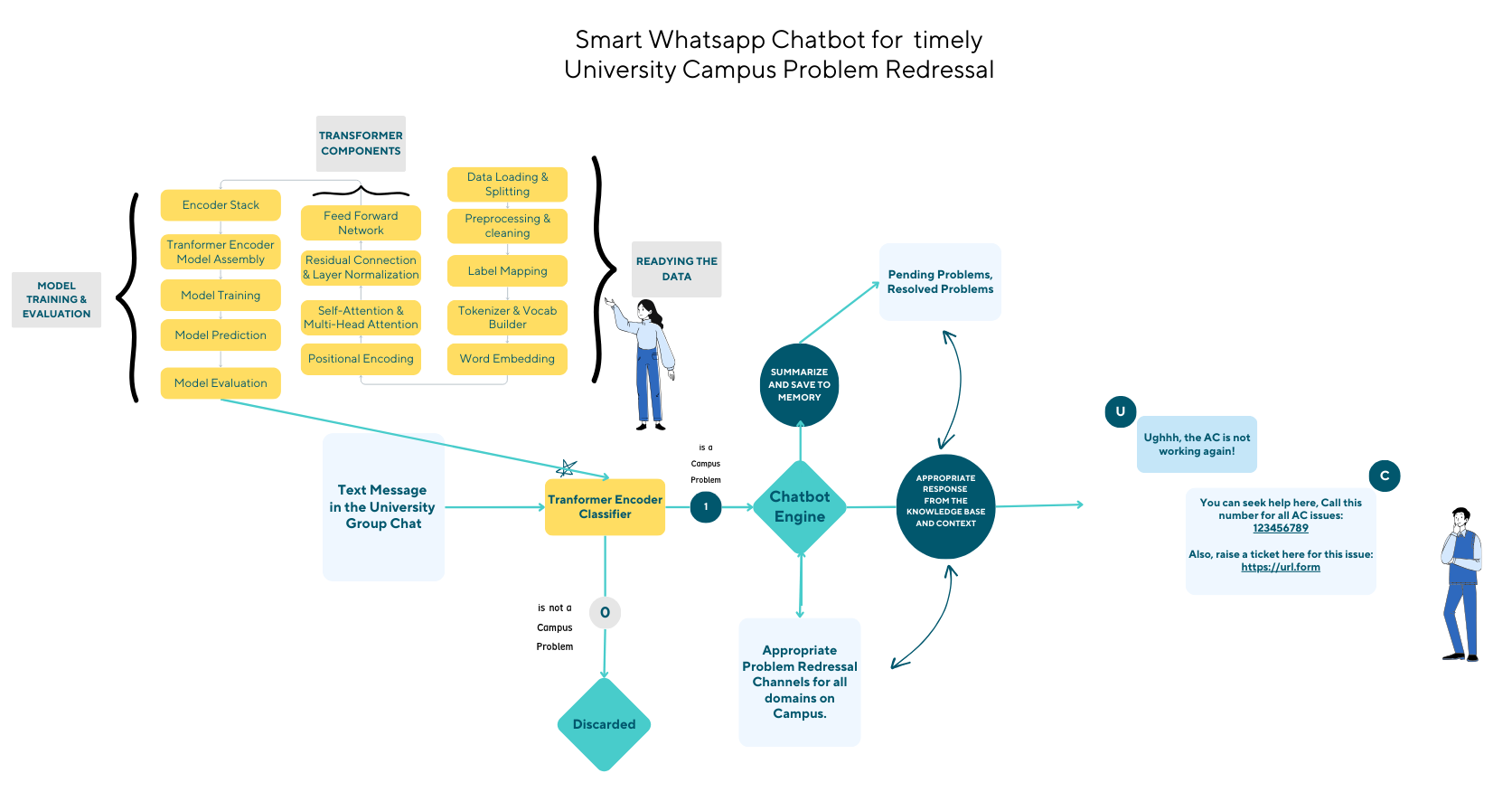
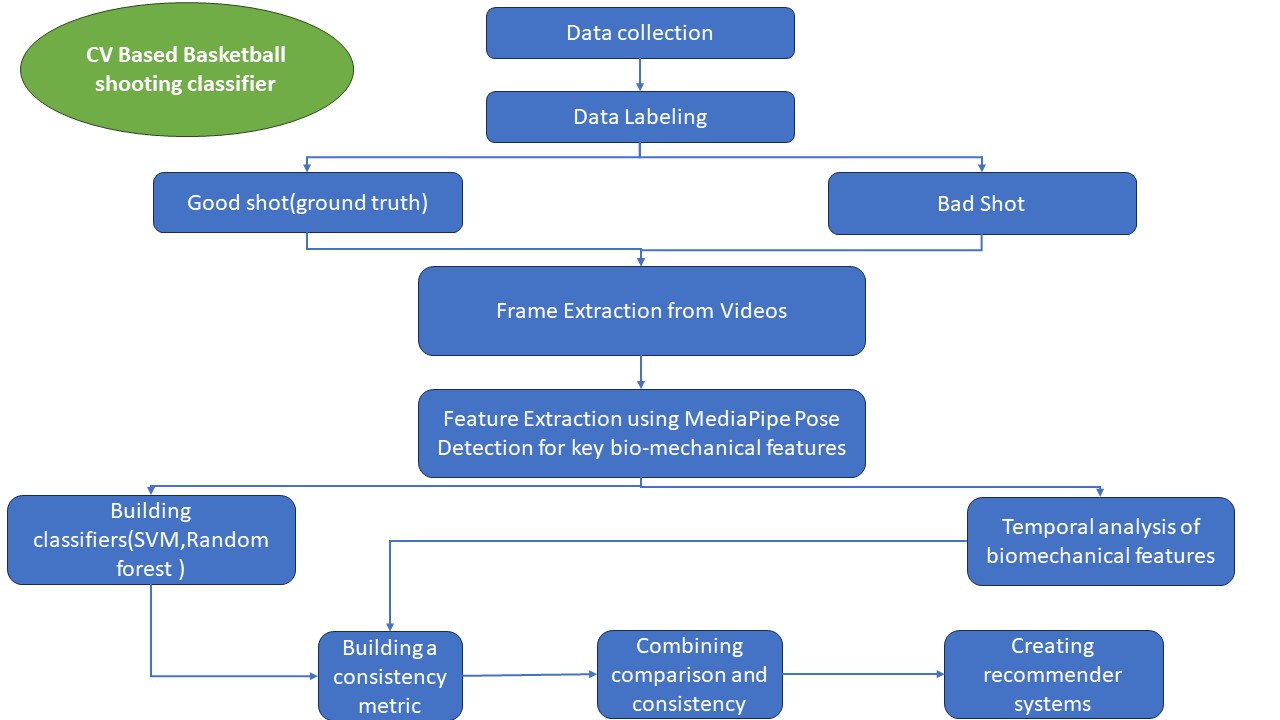
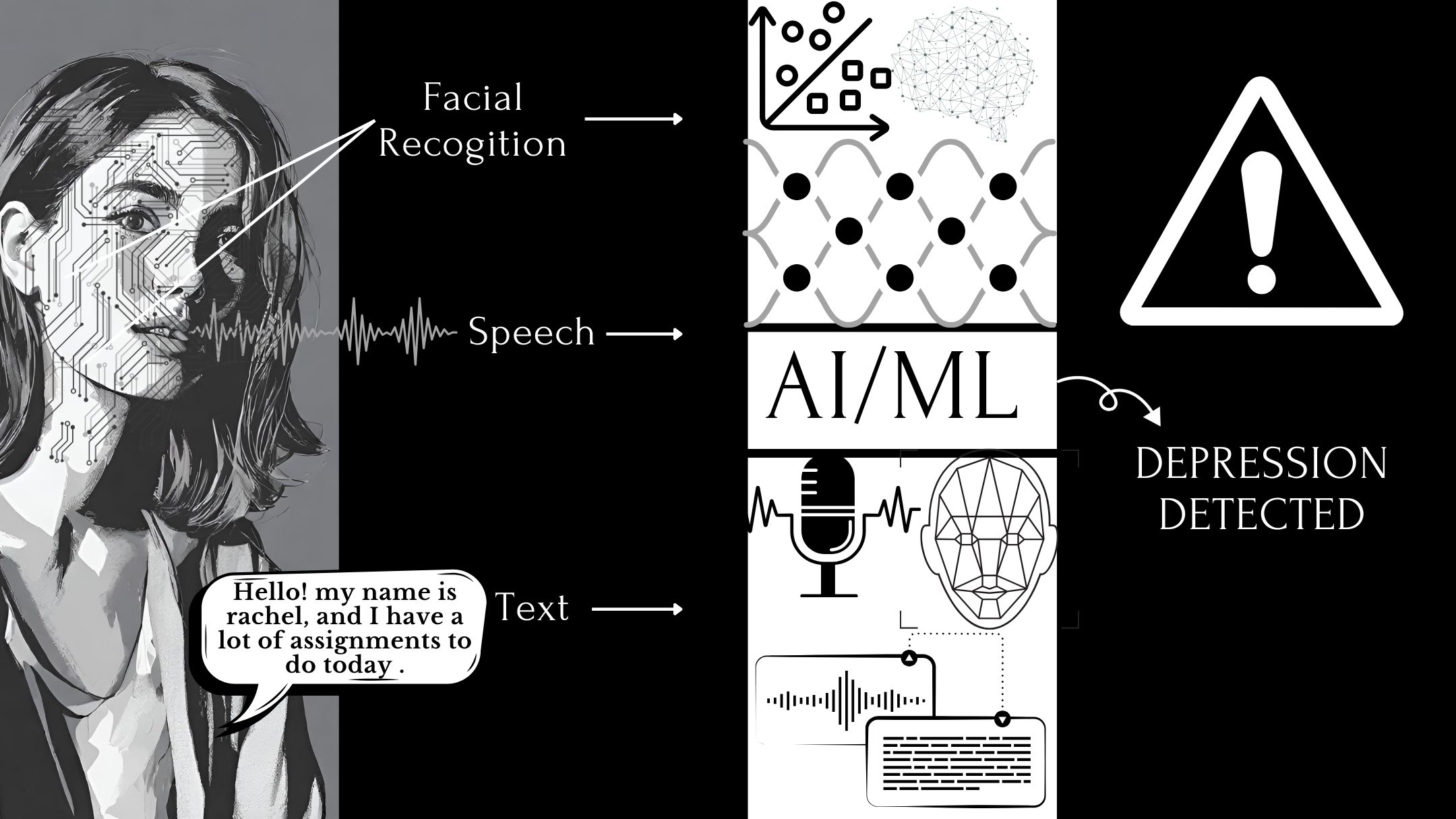
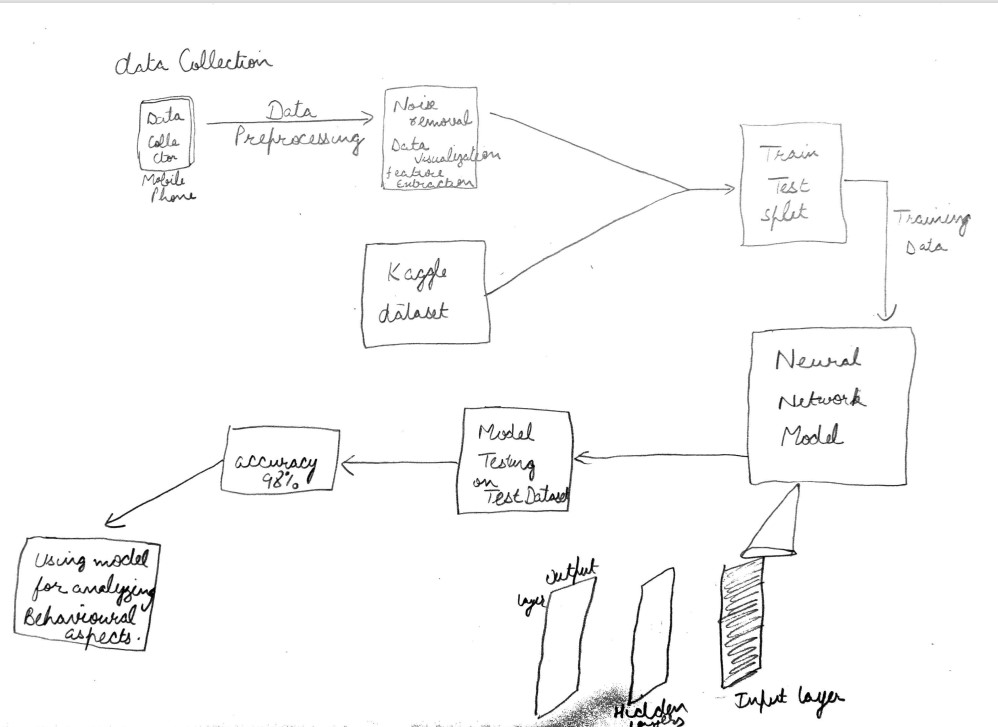
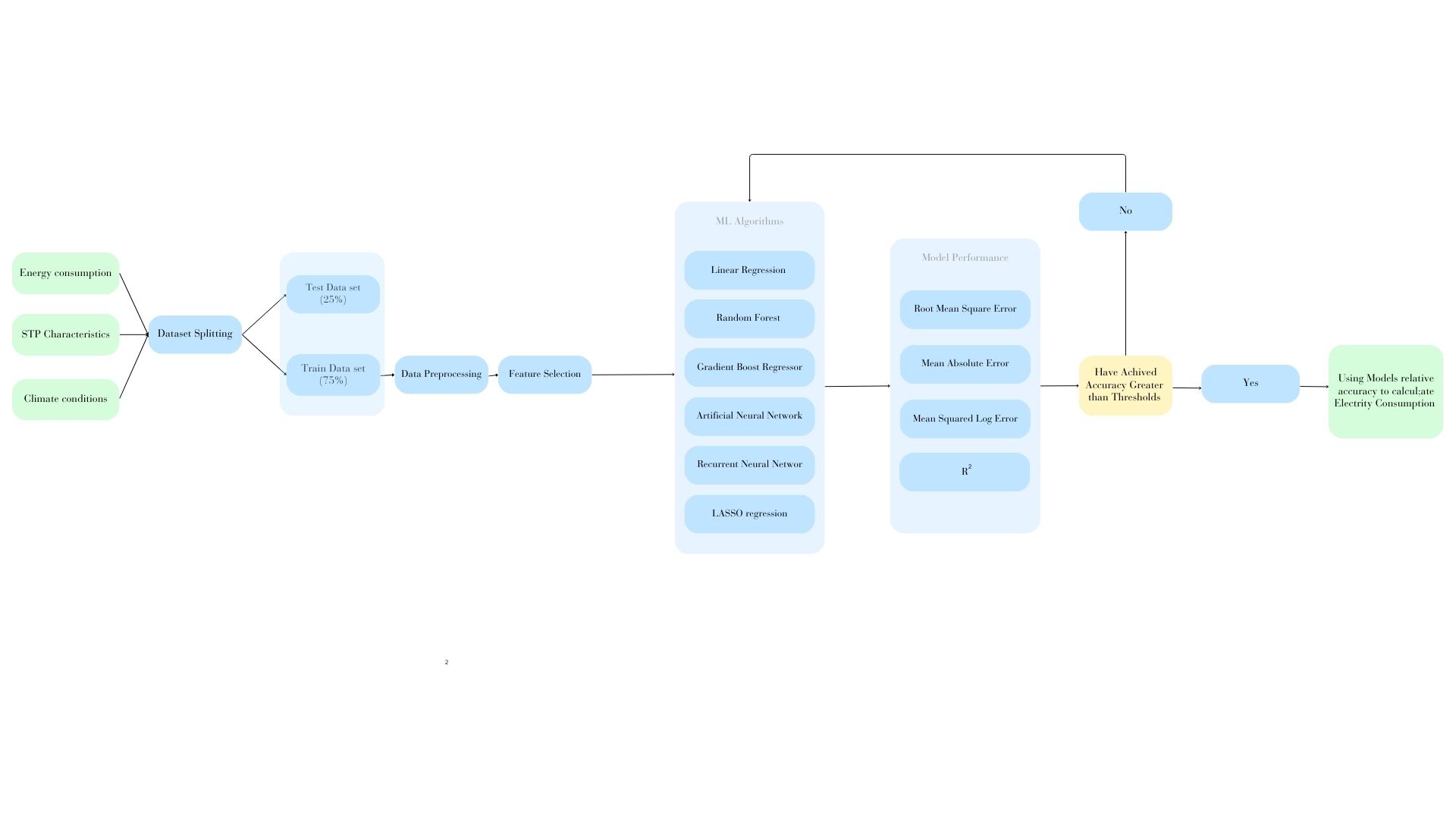
In the digital era, universities recognize the critical role of social media in connecting with students, alumni, and the wider community. However, optimizing engagement on platforms remains a challenge.
Previous studies, including Ng et al. (2023), predominantly focused on basic statistical analyses of social media data, lacking a profound integration of content analysis and real-time adaptability. To address this gap, we collected historical data from Plaksha University’s official Instagram account, incorporating posts, comments, likes, shares, and follower details.
After rigorous EDA, trend identification and handling missing values, we integrated We employed a combination of TF-IDF with SVM for content analysis and Random Forest Regression for engagement prediction. Algorithm choices were meticulously driven by their ability to handle linear and non-linear, textual and numeric data.
Performance metrics such as MAE, RMSE, Accuracy, Precision, Recall and F1-Score to showcase model effectiveness. Lower MAE and RMSE values indicated accurate user engagement predictions and higher F1-Scores reflected a better understanding of effective content types.
This project is aimed at contributing to tailoring effective content strategies in real-time, leading to enhanced engagement and a more vibrant social media presence for Plaksha.