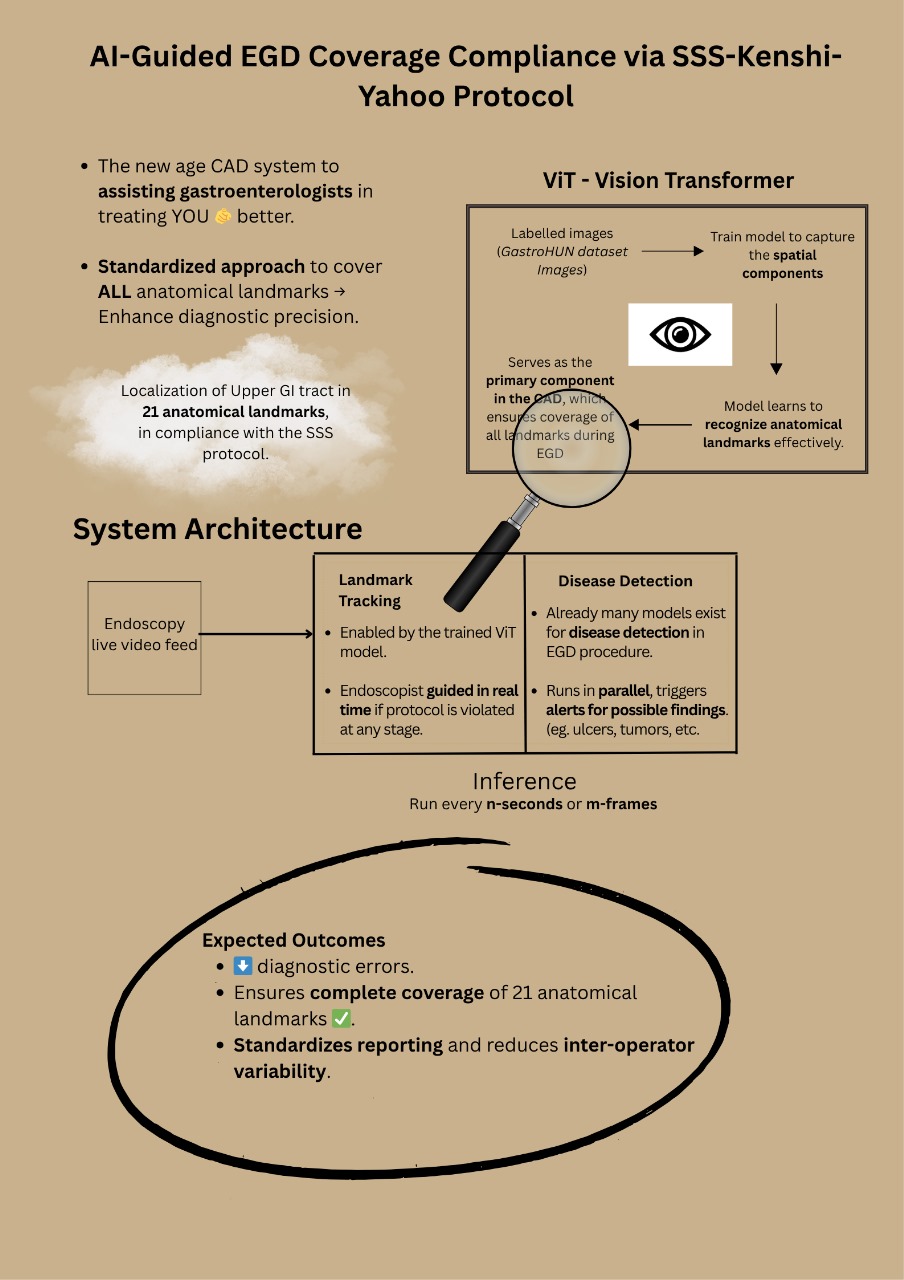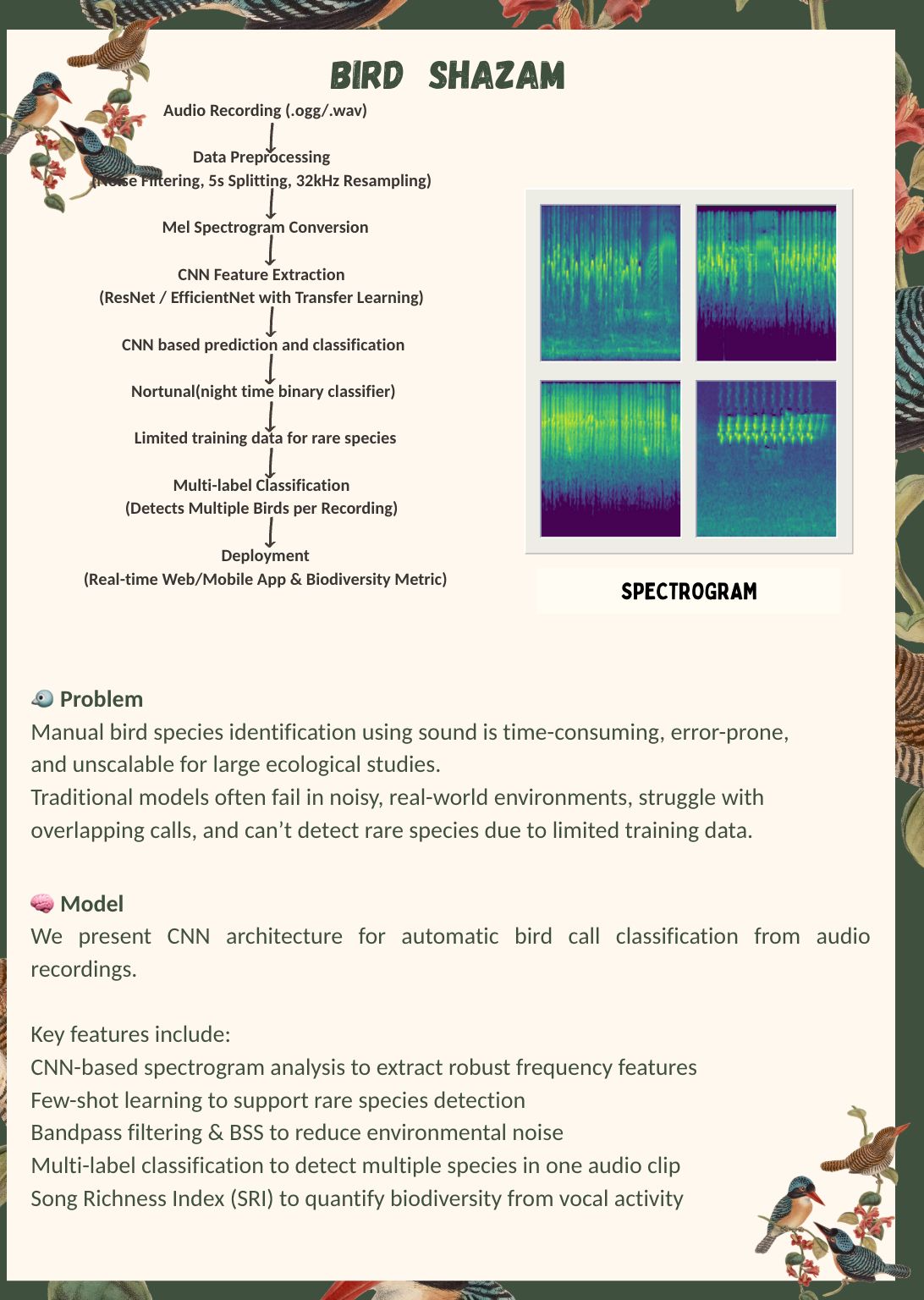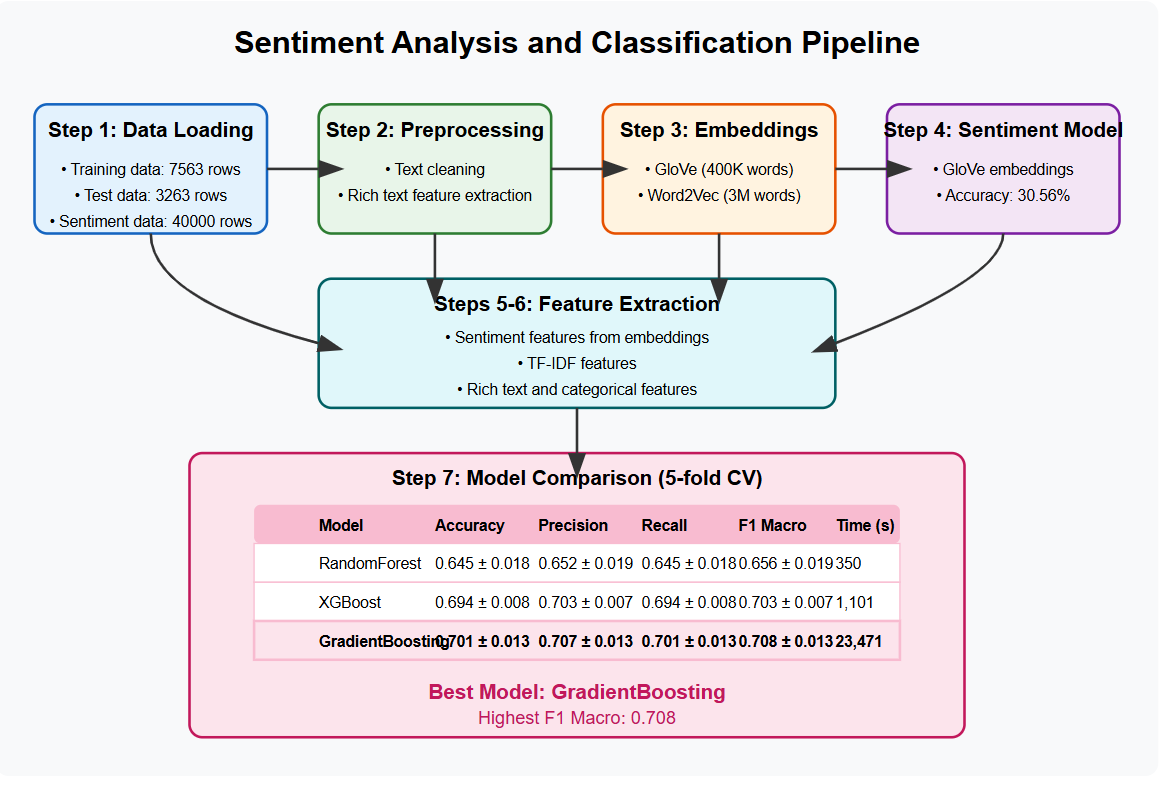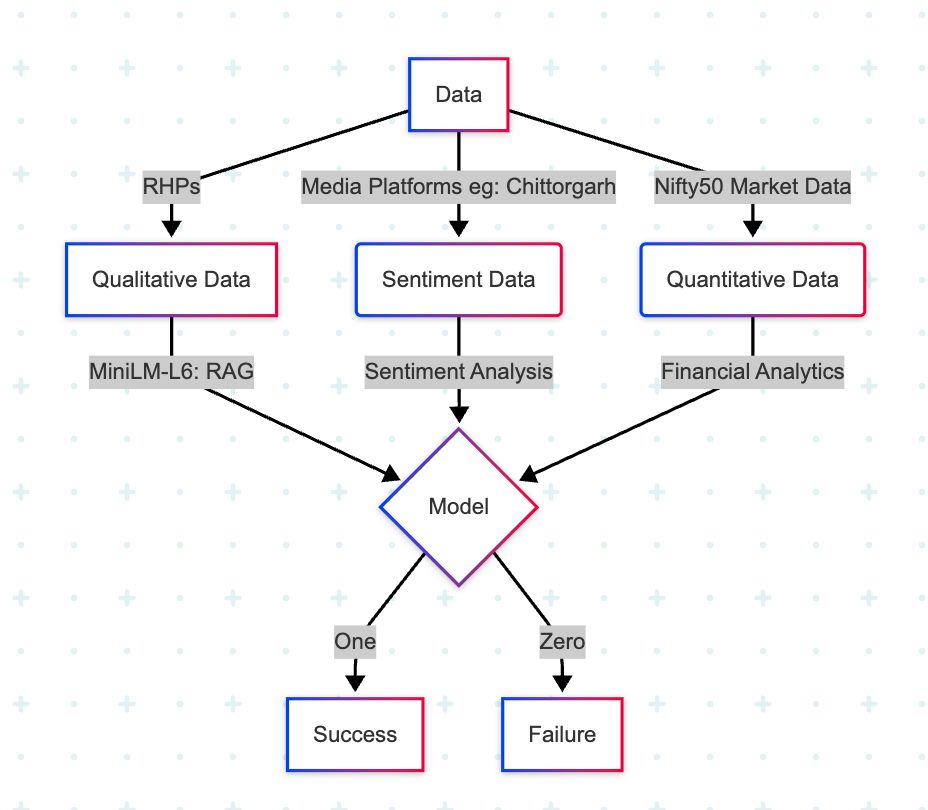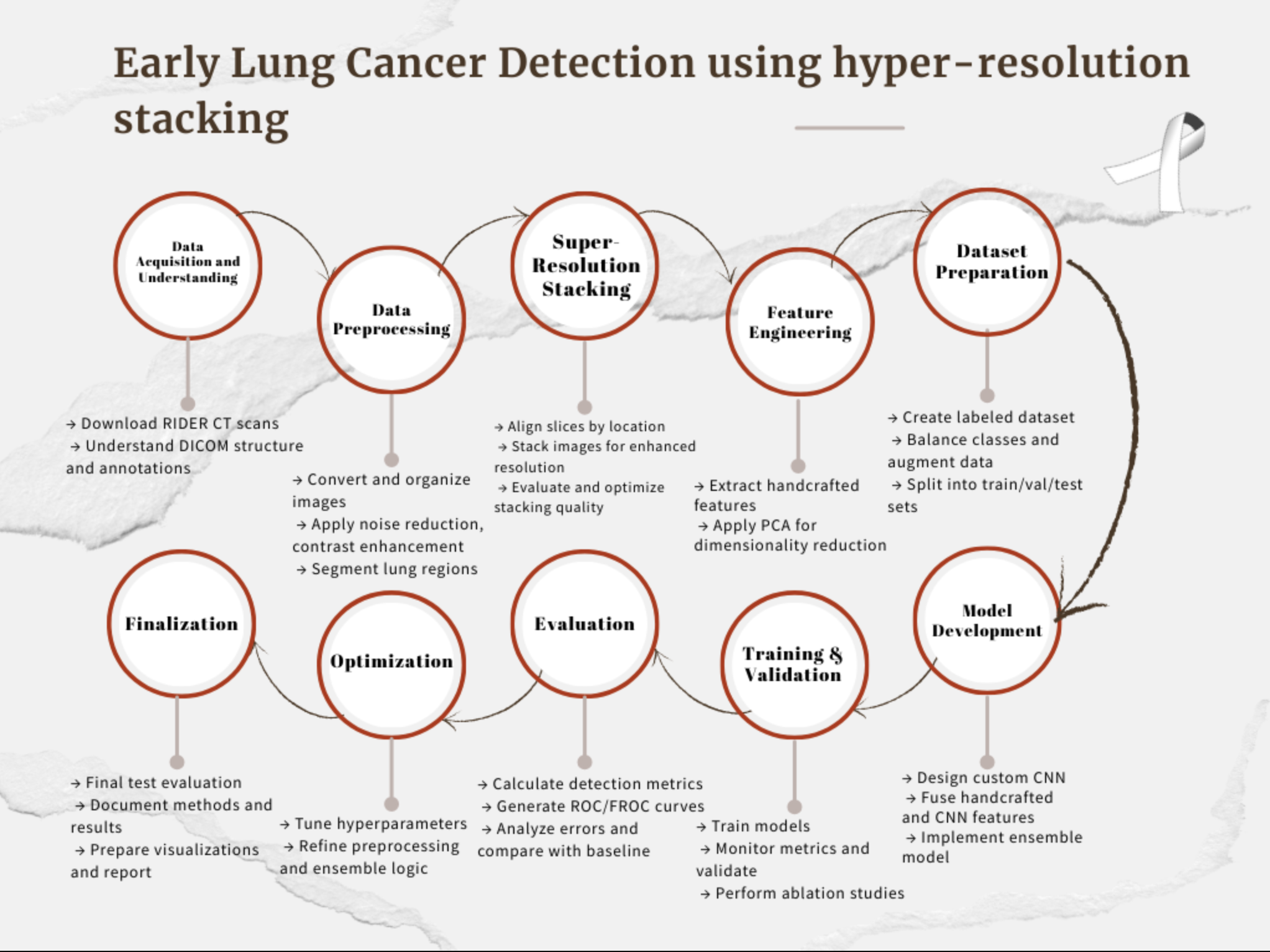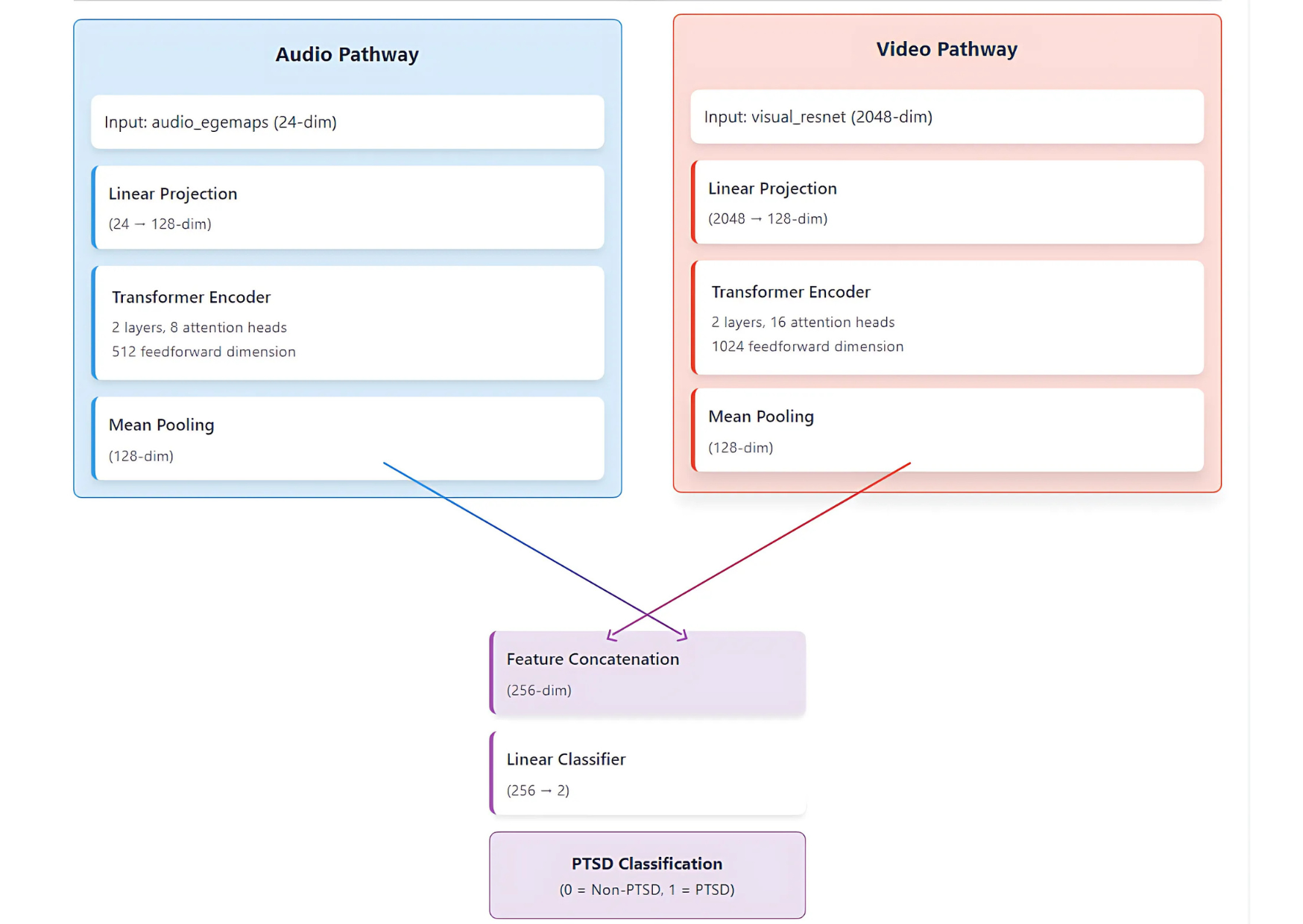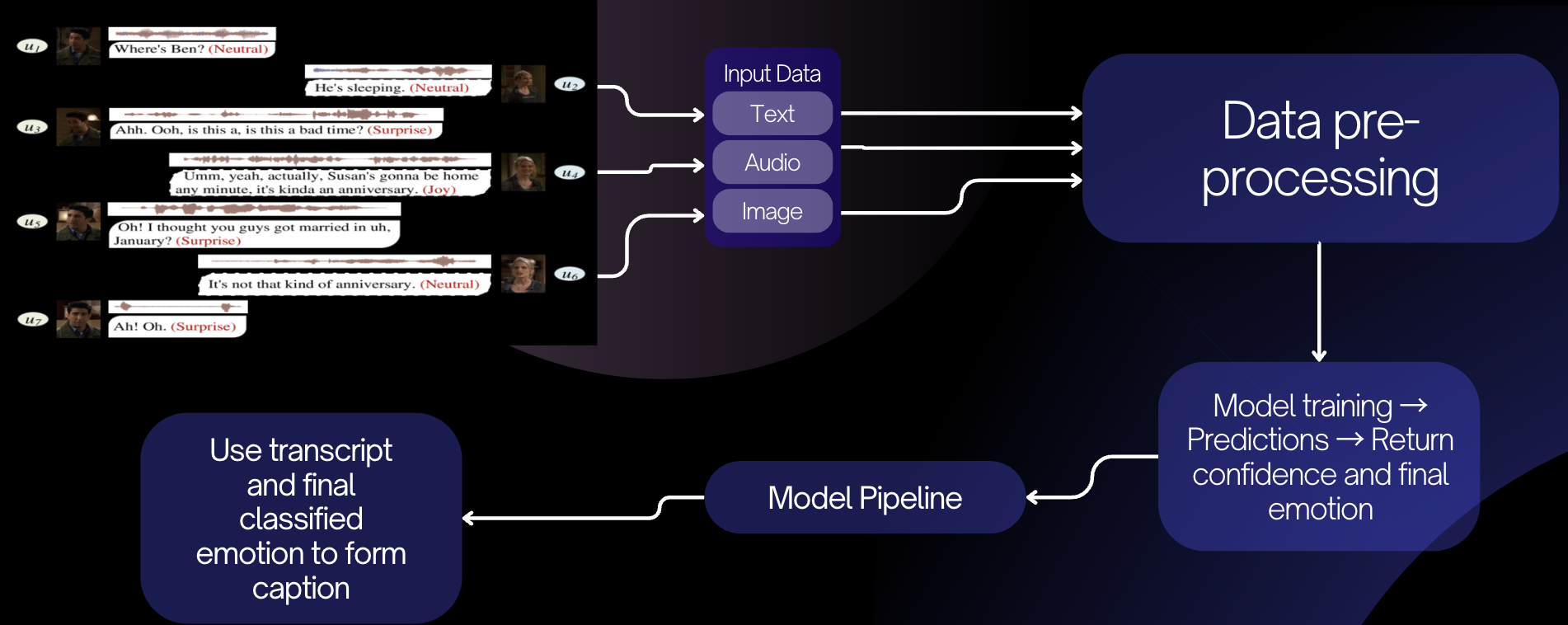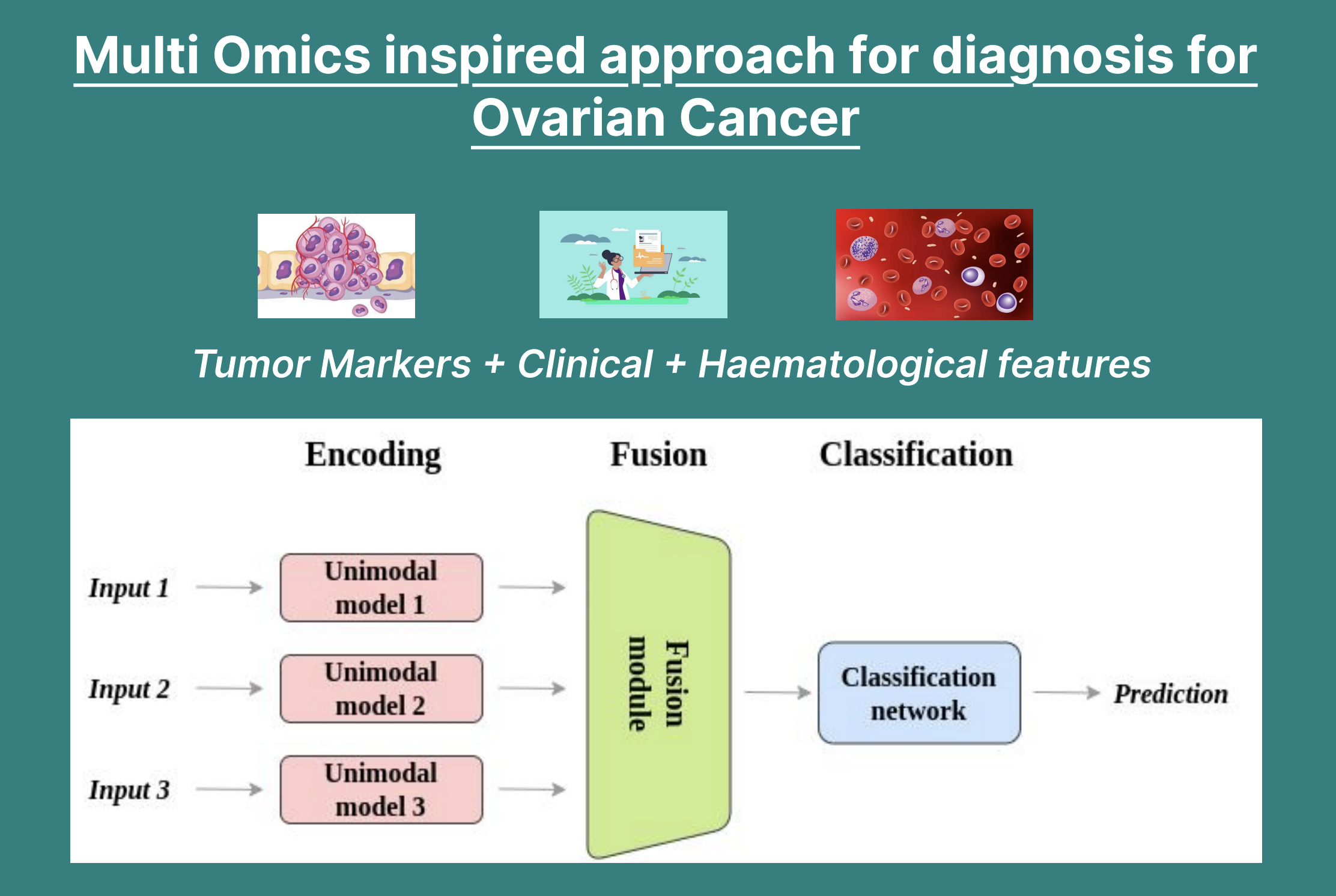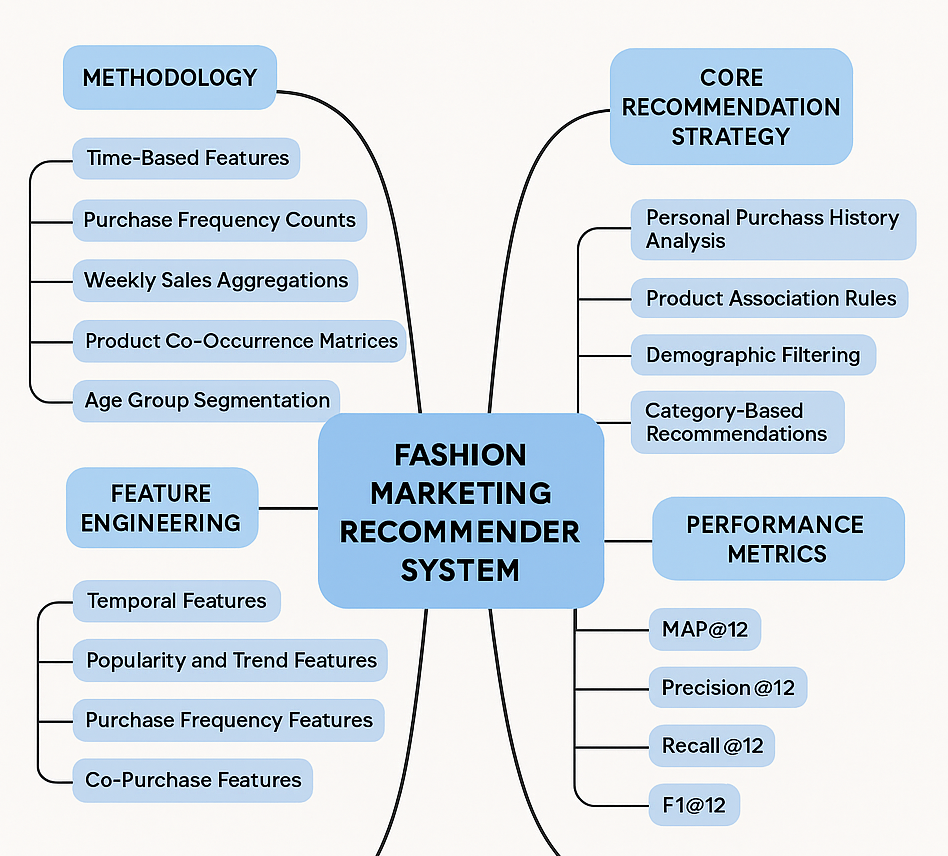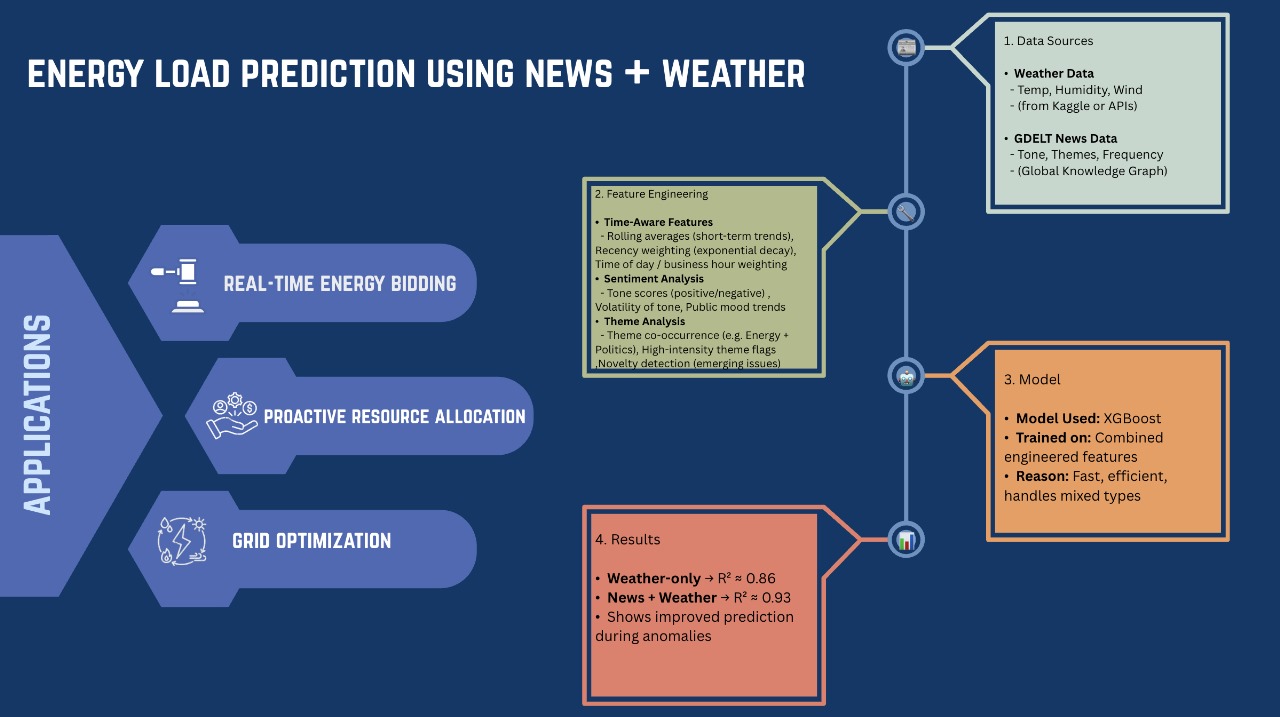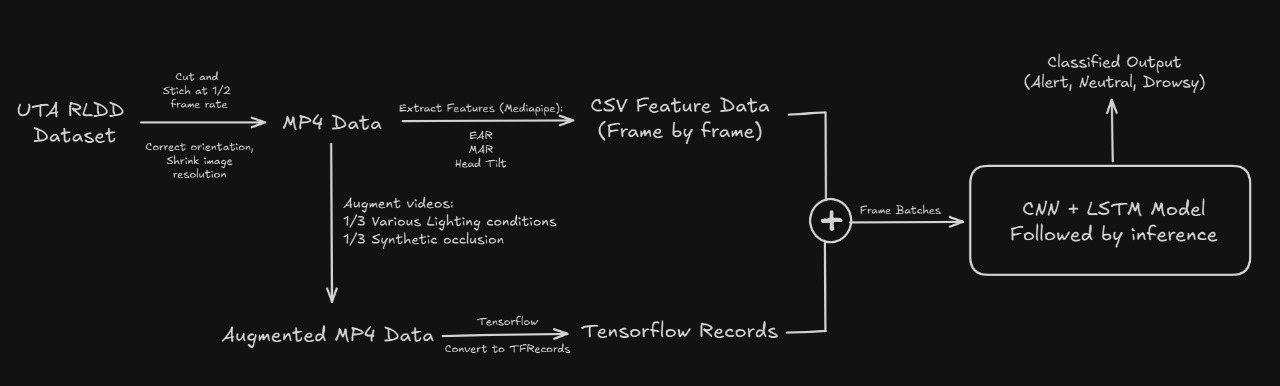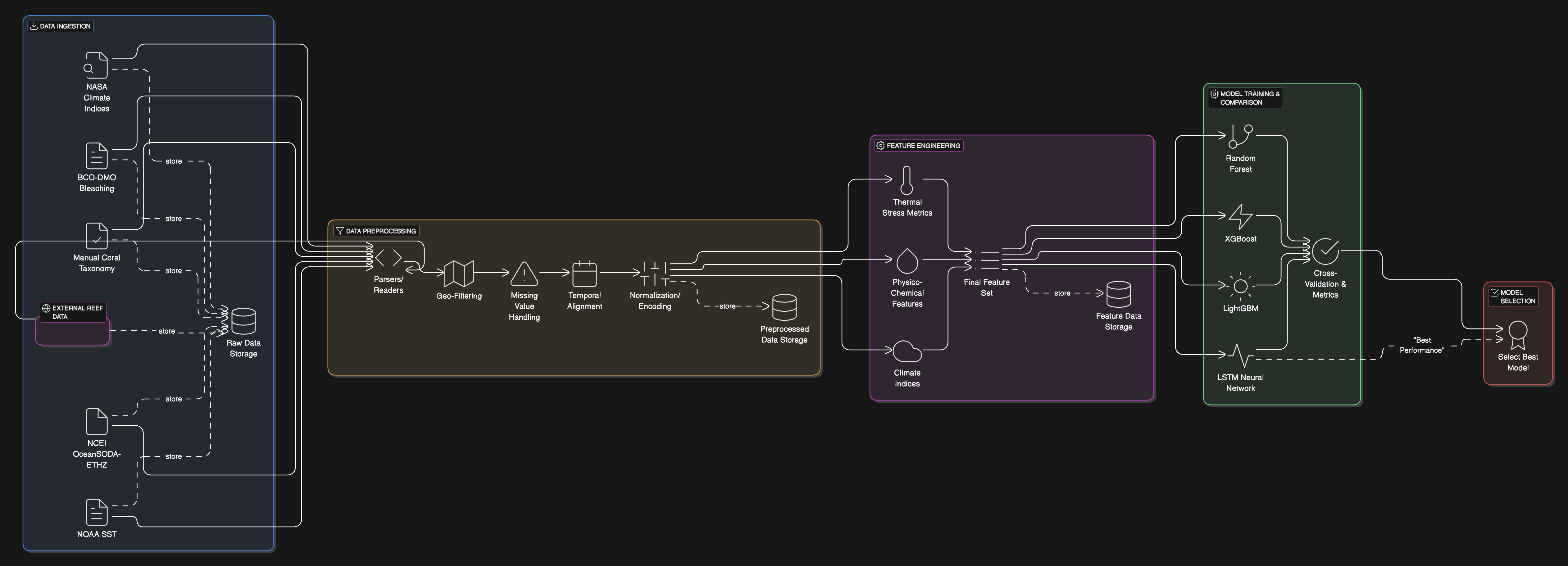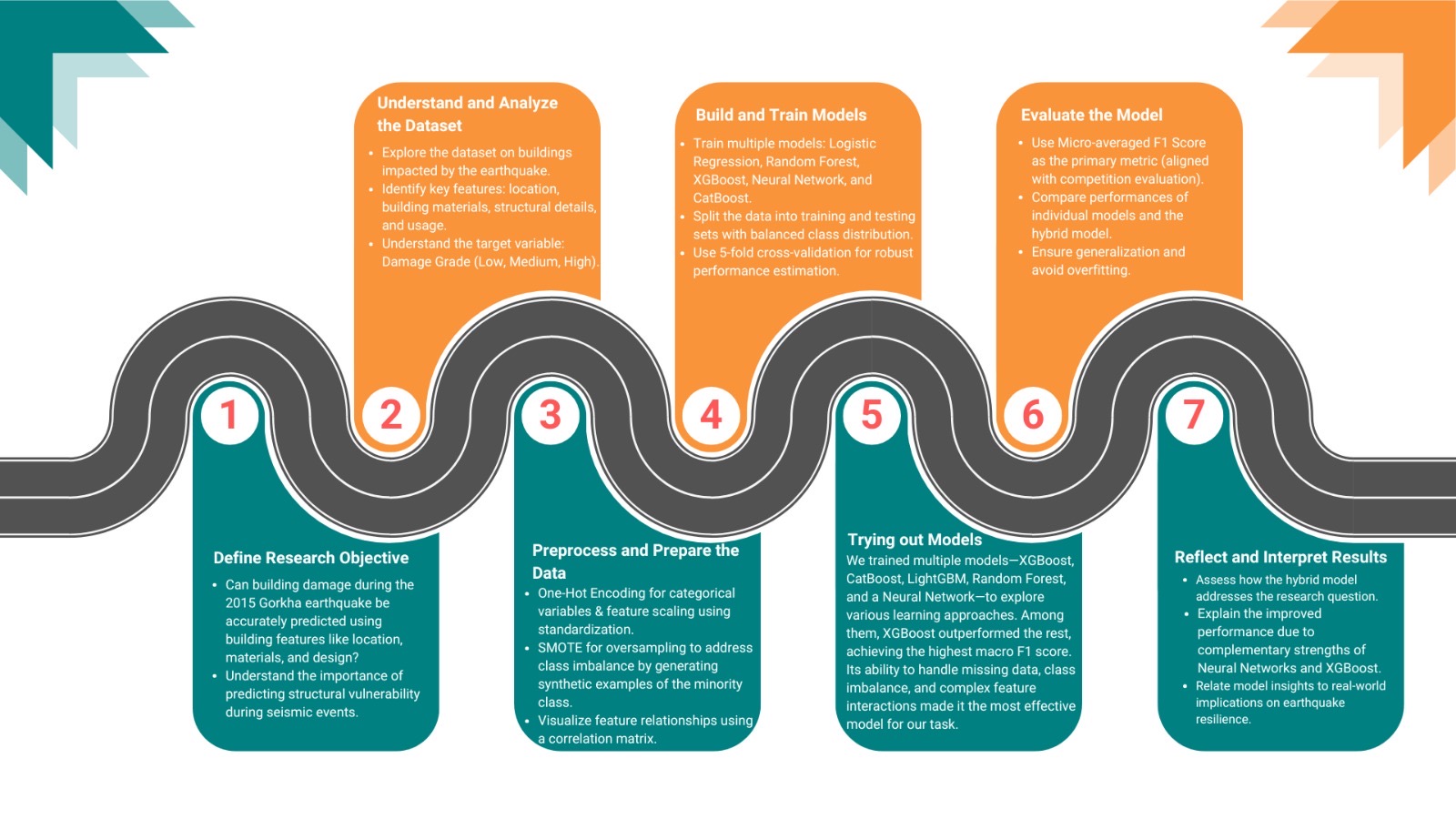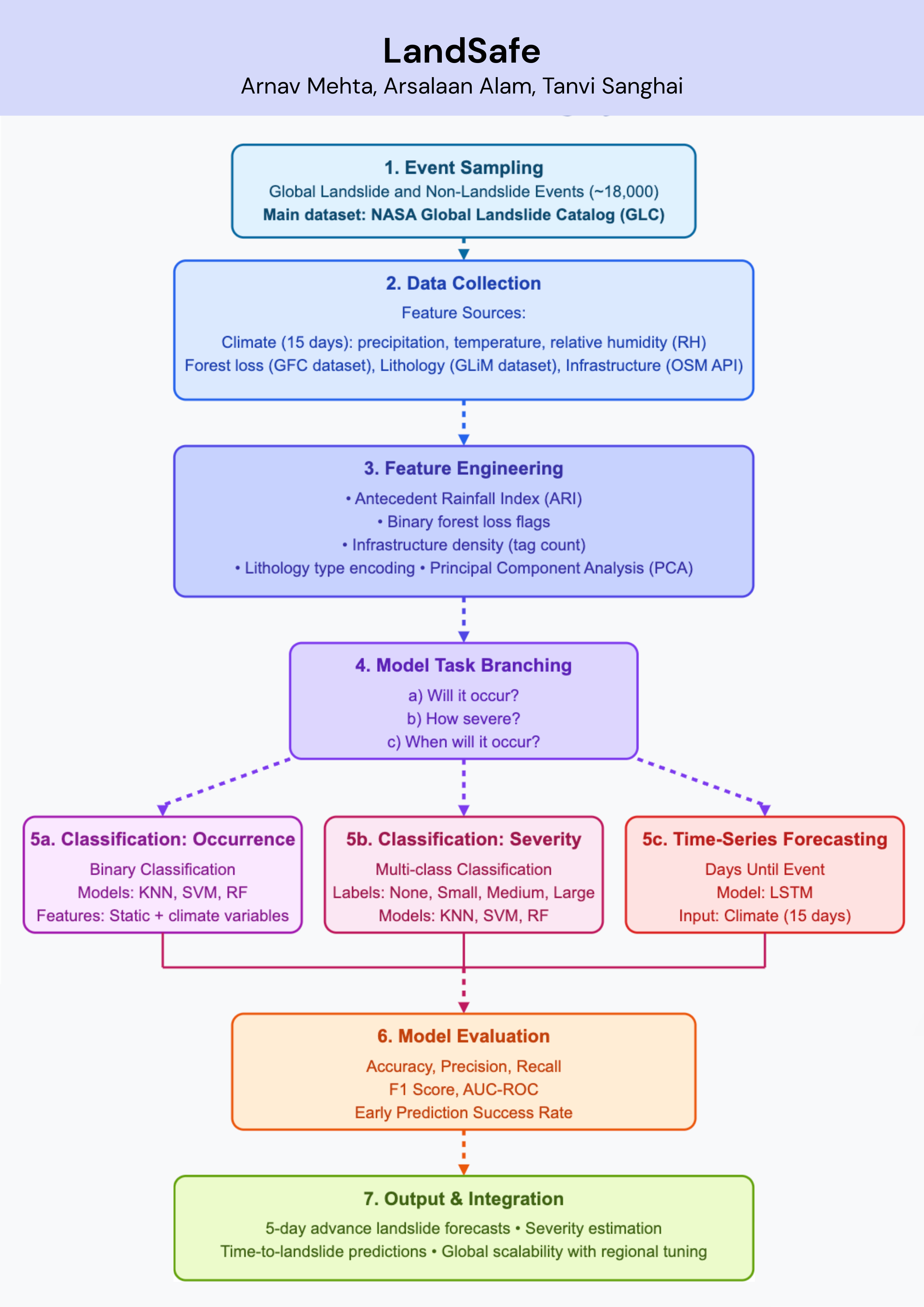
Landslides pose serious threats to human life and infrastructure, yet timely forecasting remains a major challenge due to the complex interplay of environmental and anthropogenic factors. Existing systems such as NASA’s LHASA offer limited detection accuracy (8–60%) and operate on basic decision tree models with static features. This study presents LandSafe, a machine learning-based landslide forecasting system trained on over 18,000 events globally. The system integrates dynamic climate variables: precipitation, temperature, and humidity (retrieved for the 15 days preceding each incident). This methodology also includes attributes such as forest loss, lithology, and infrastructure proximity.
Feature engineering methods include the computation of the Antecedent Rainfall Index (ARI), binary forest cover loss & PCA to reduce dimensions. For classification tasks, K-Nearest Neighbors (KNN), Support Vector Machine (SVM), and Random Forest (RF) models are evaluated to determine landslide occurrence and severity. A time-series LSTM model is employed to predict the number of days until a potential landslide event, leveraging historic and temporal dependencies in climate data. Results are benchmarked against current systems using precision, recall, F1-score, and AUC-ROC metrics. Landsafe offers improved accuracy and generalizability across diverse geographies, making it a viable and scalable solution for proactive landslide early warning.