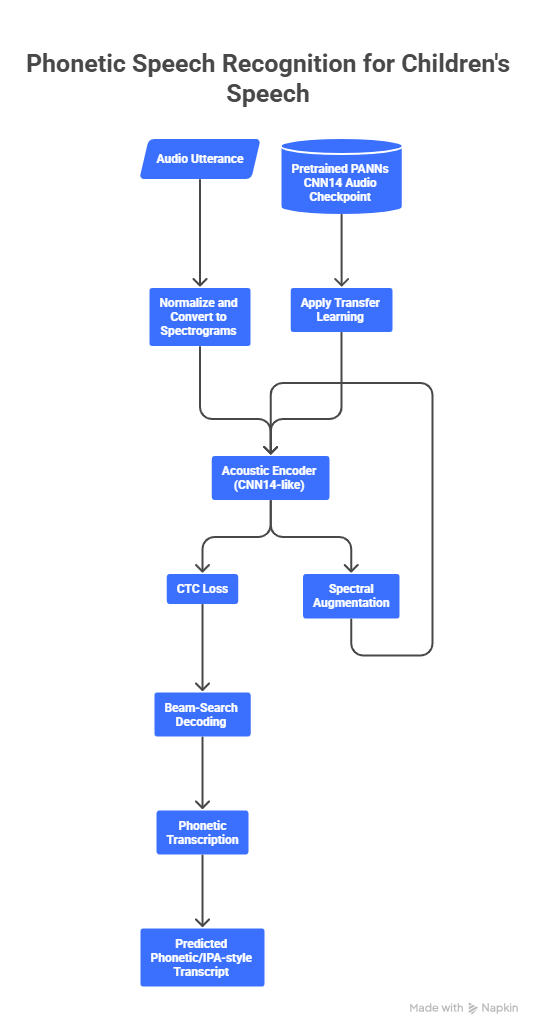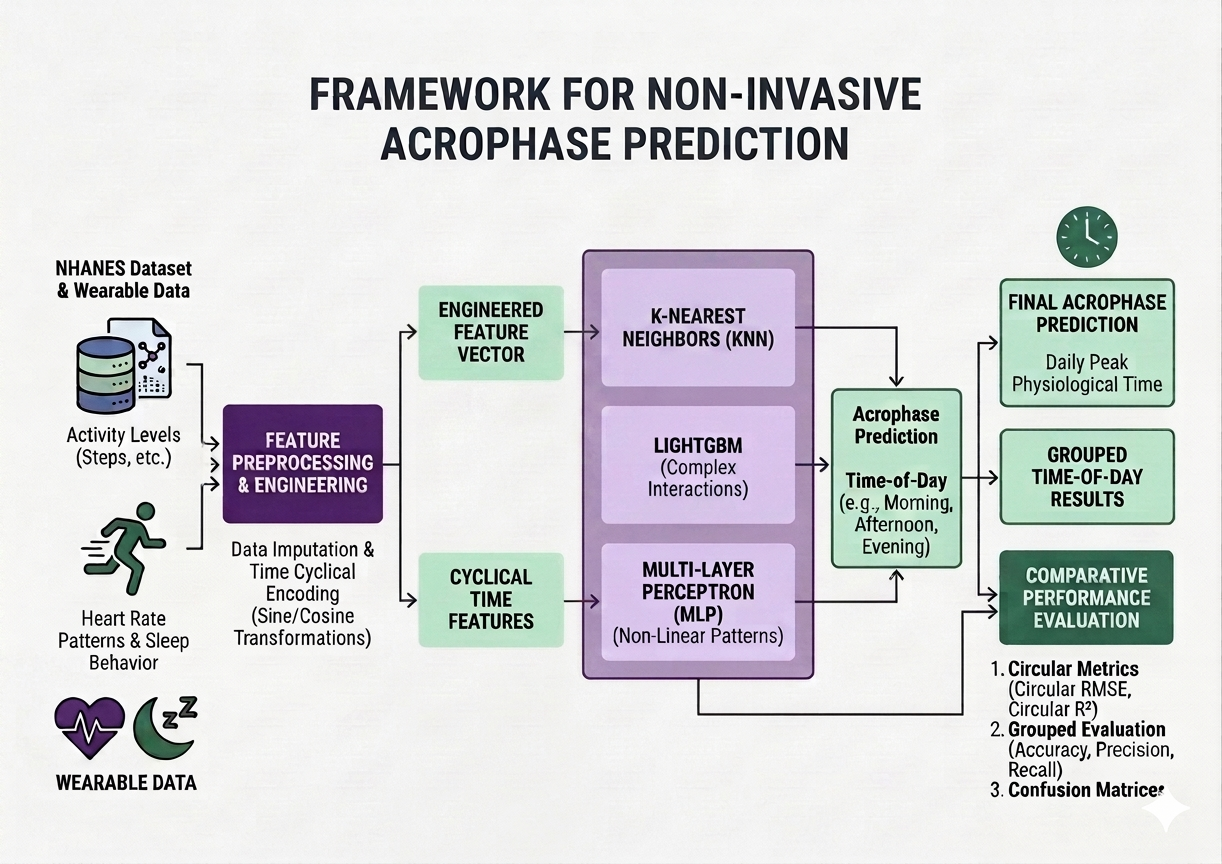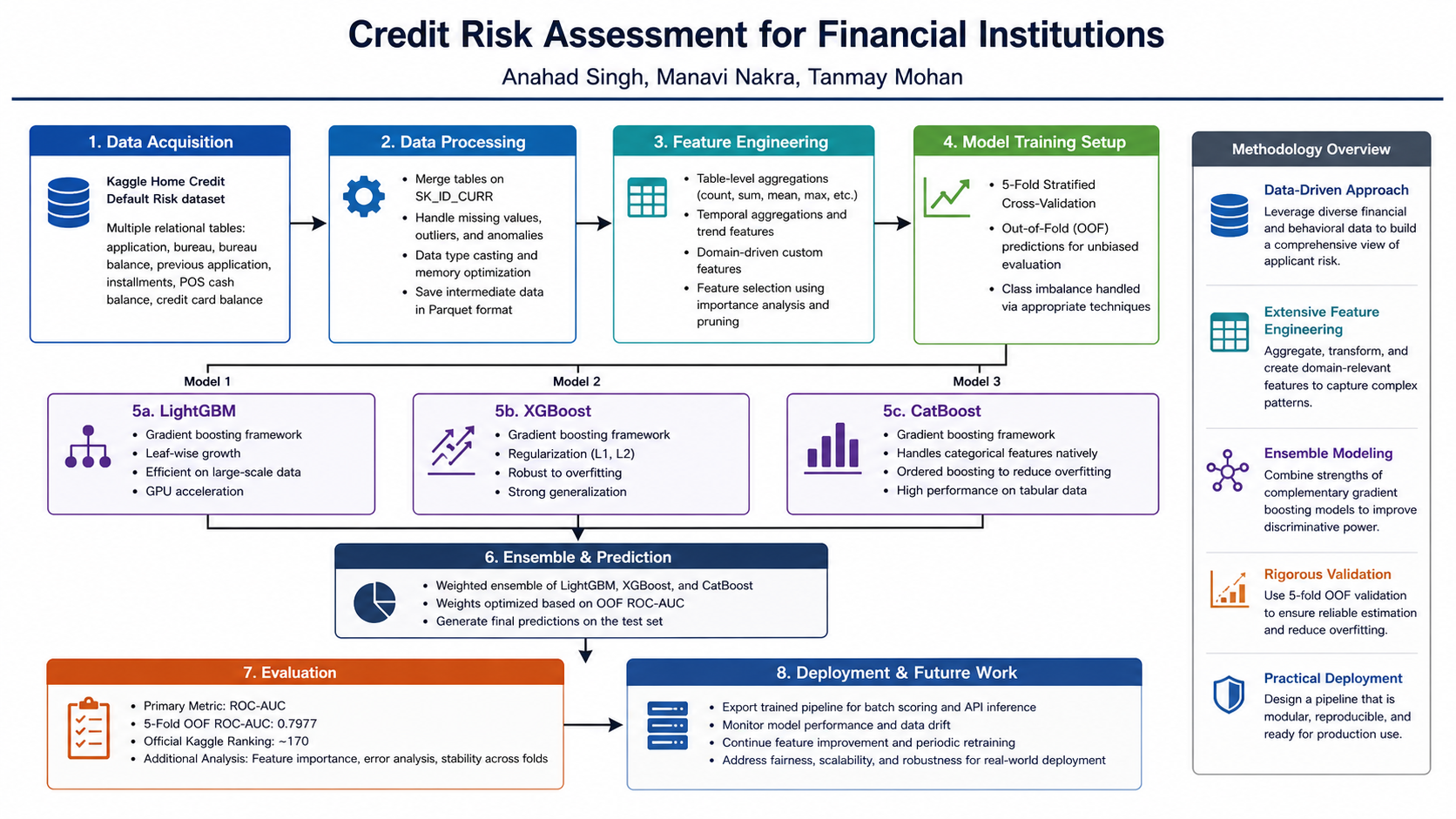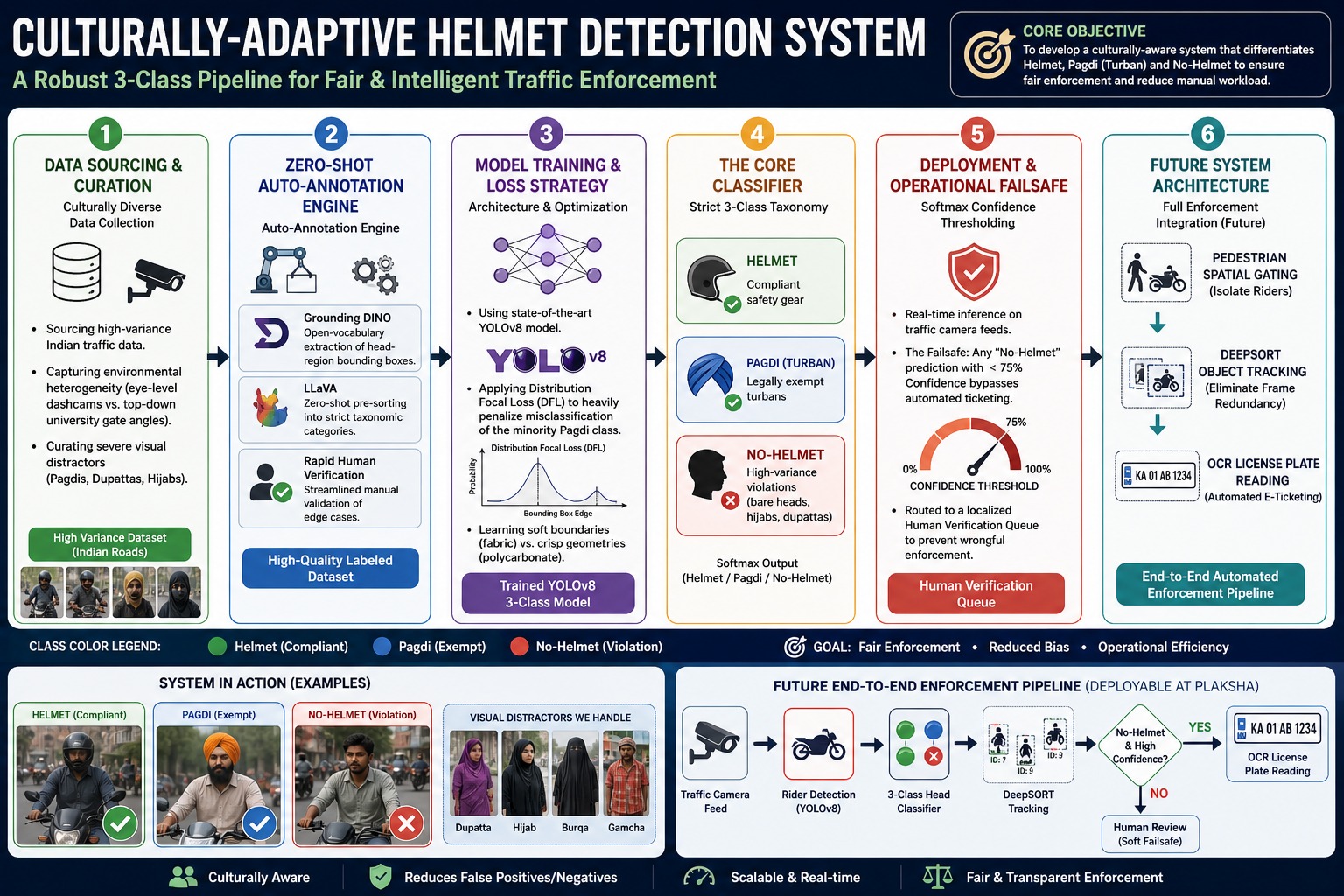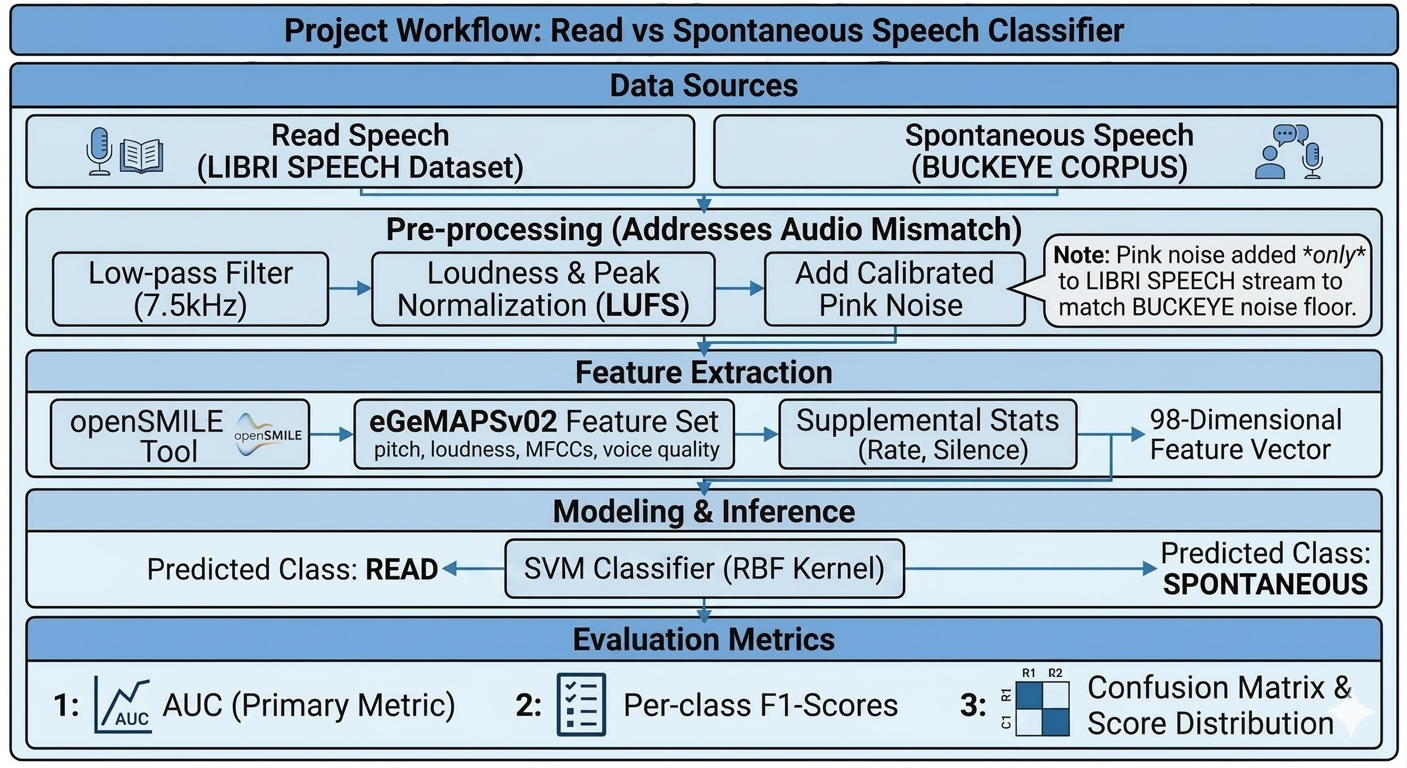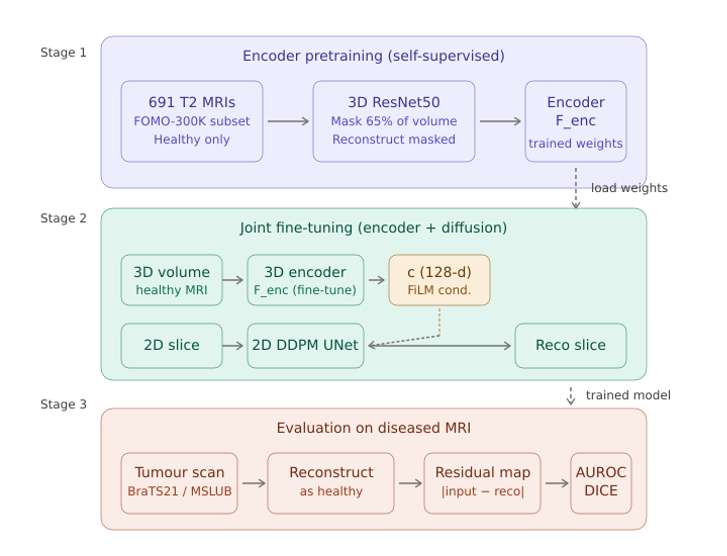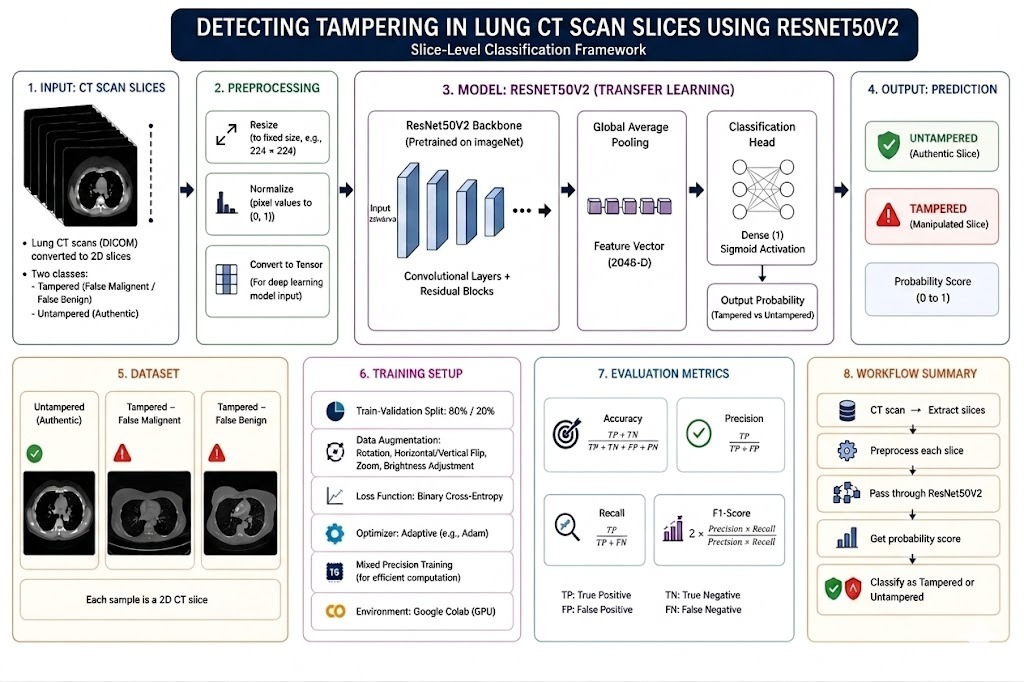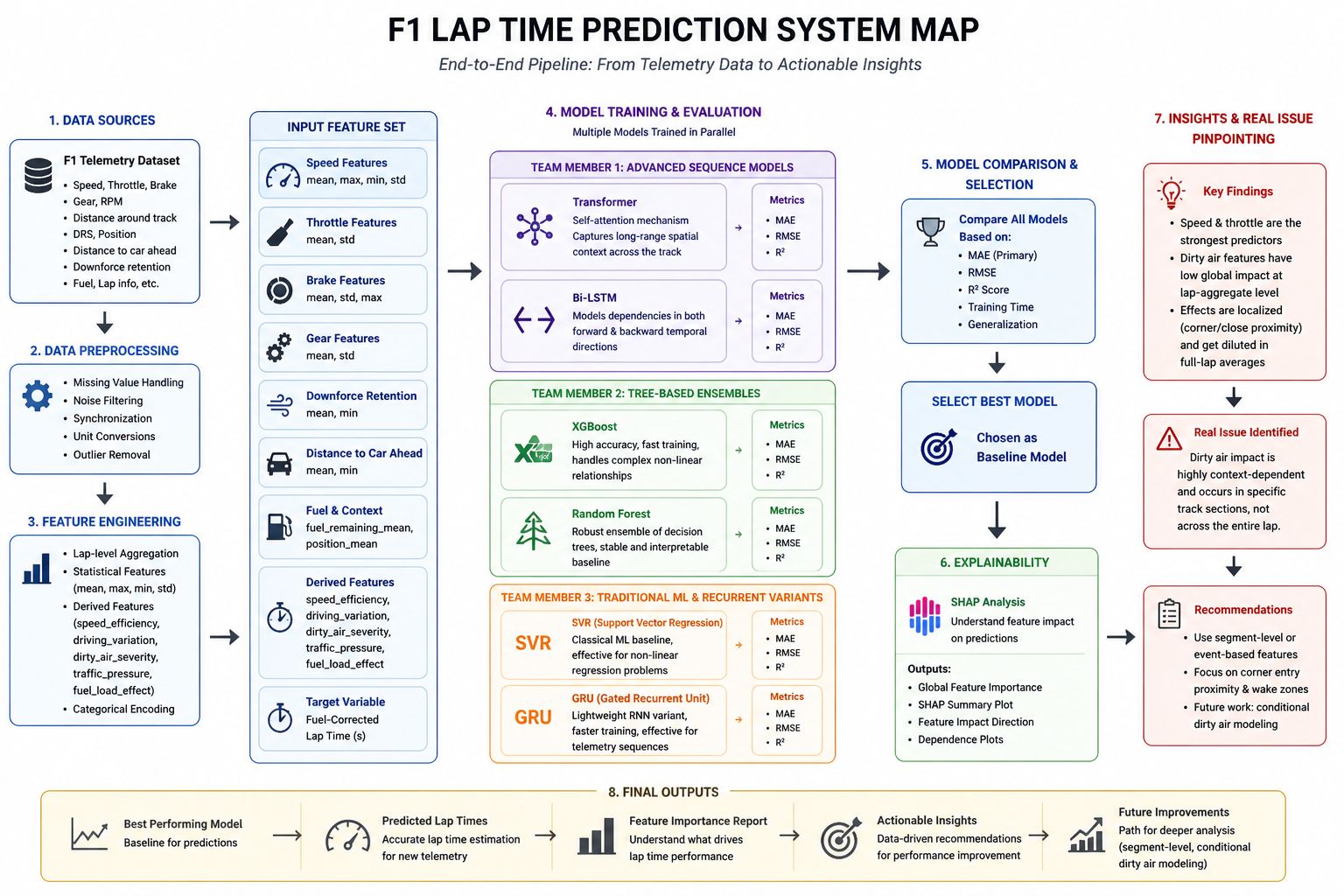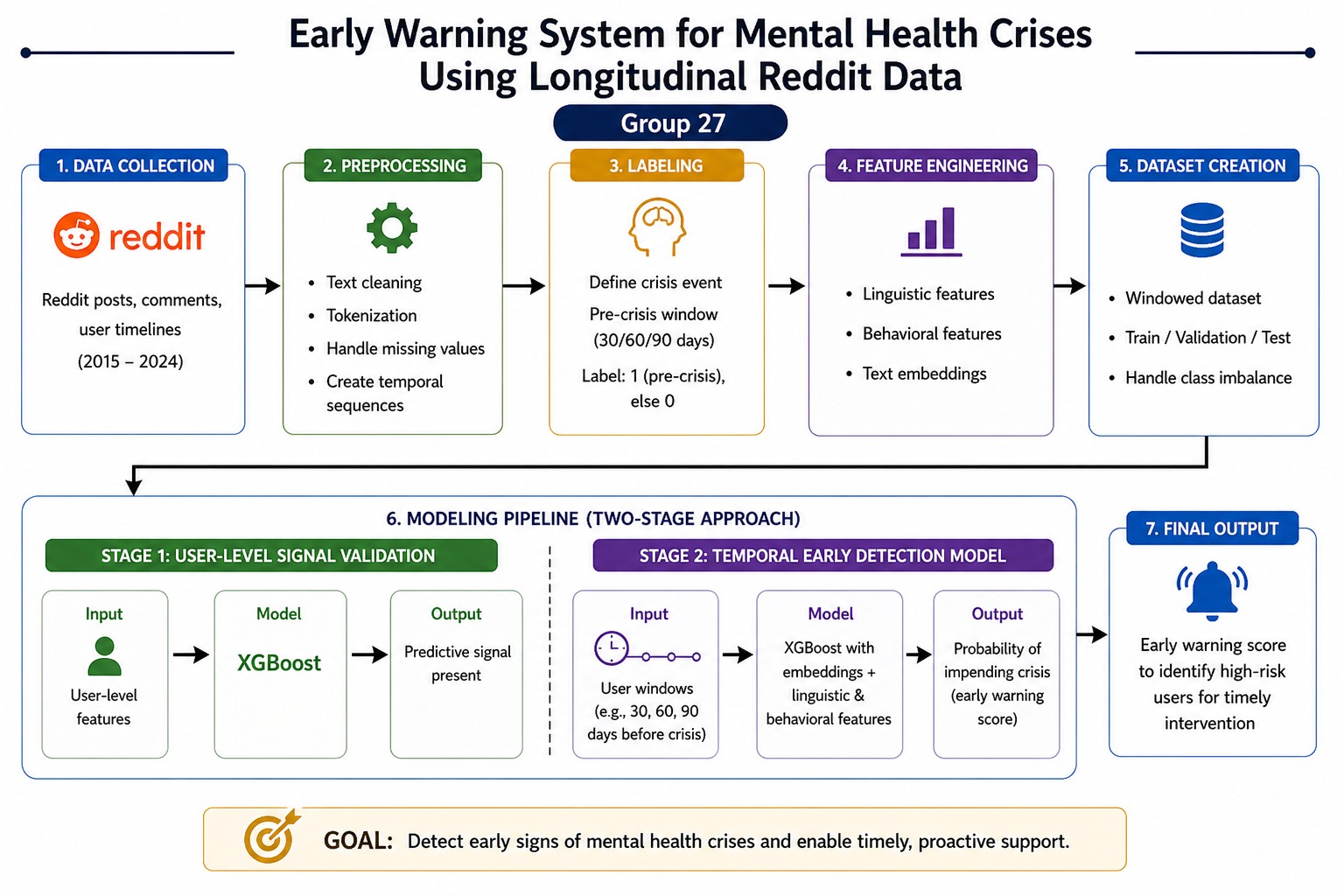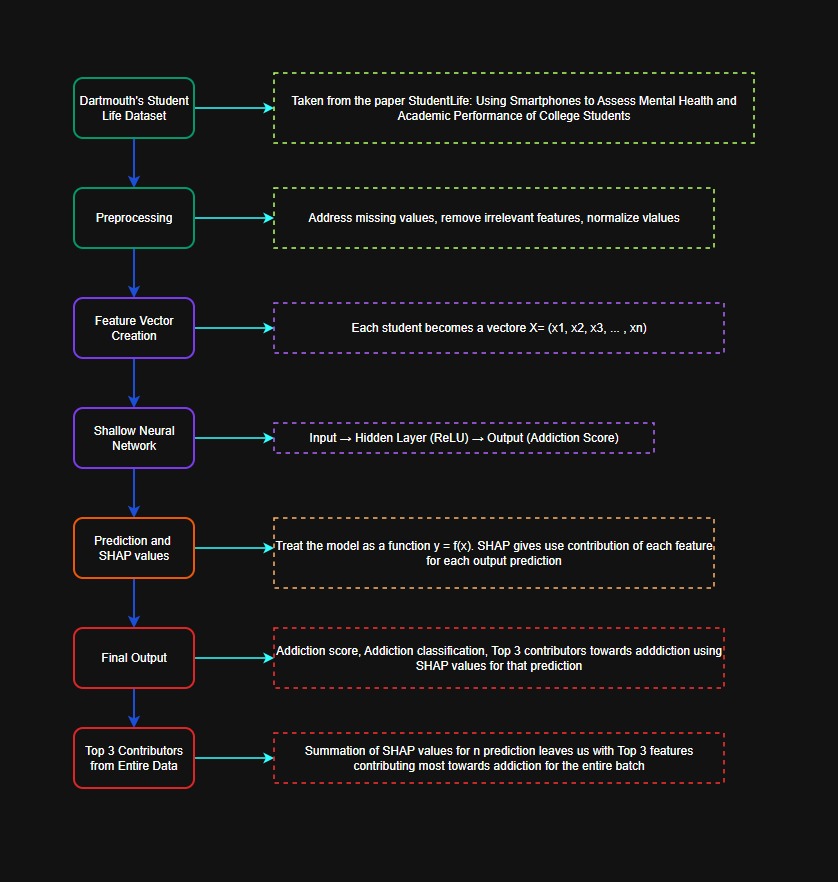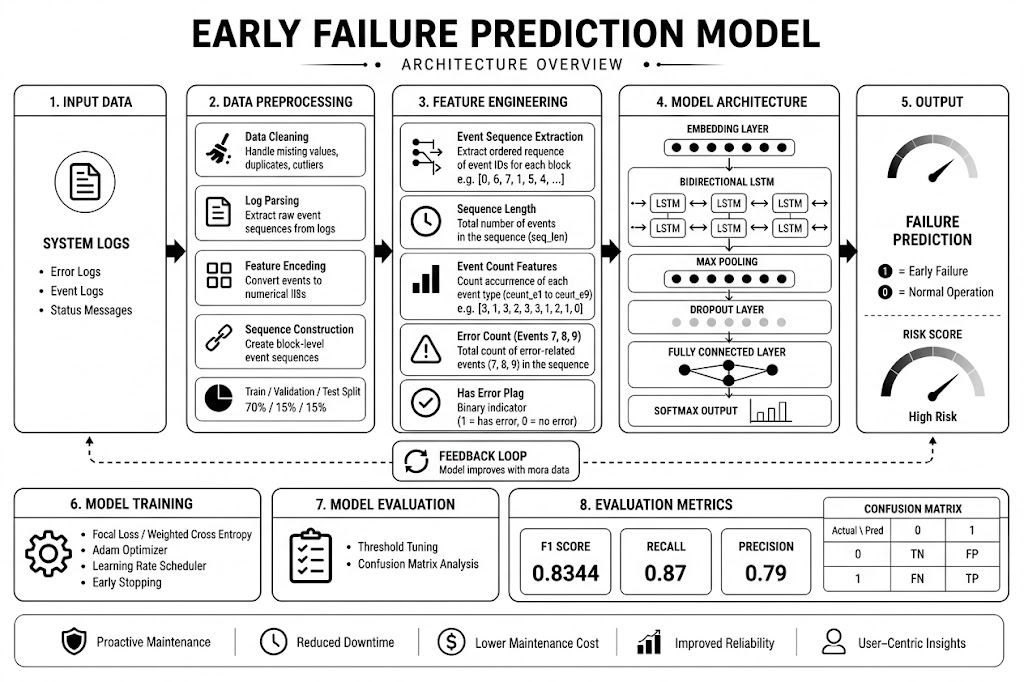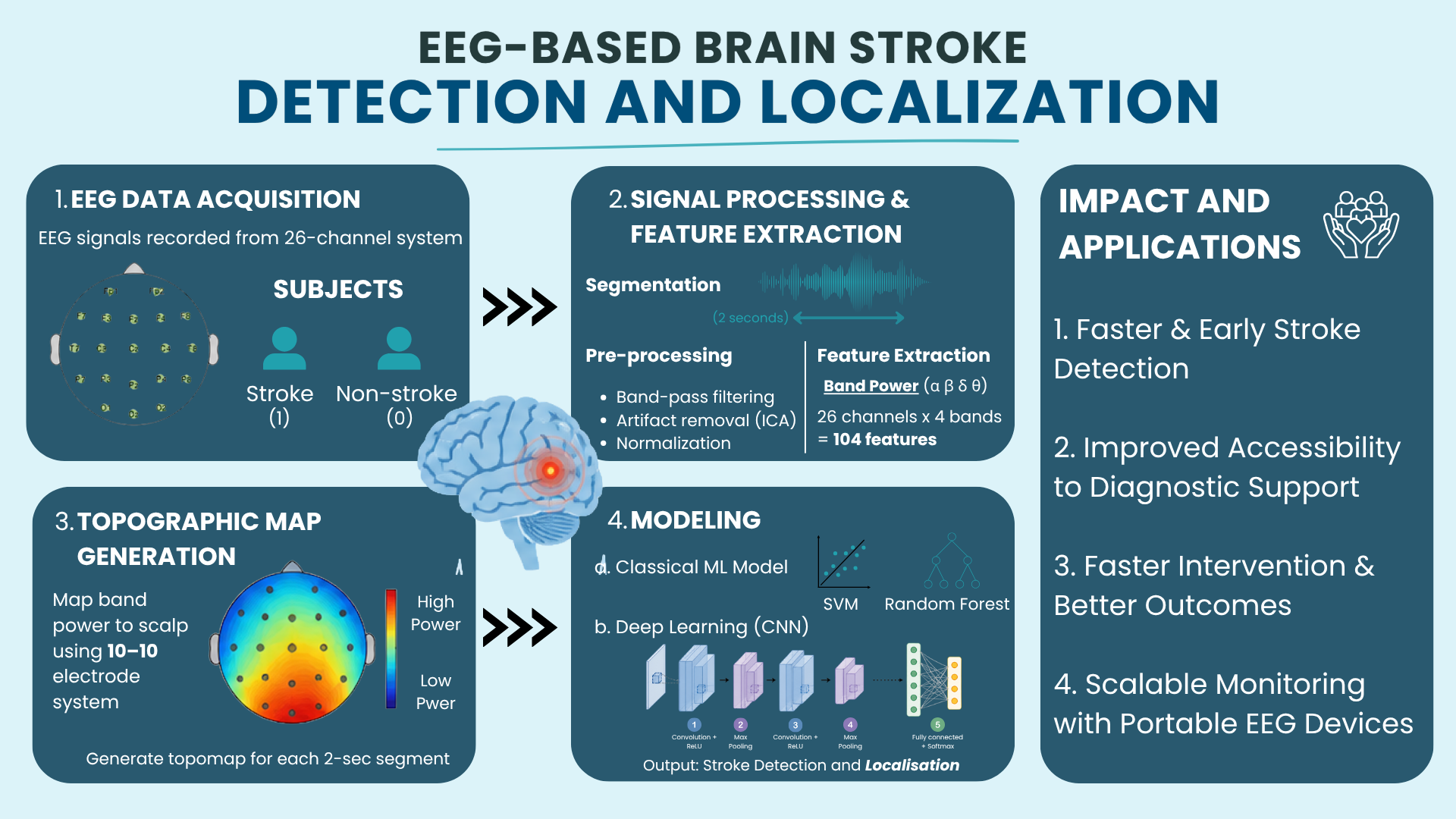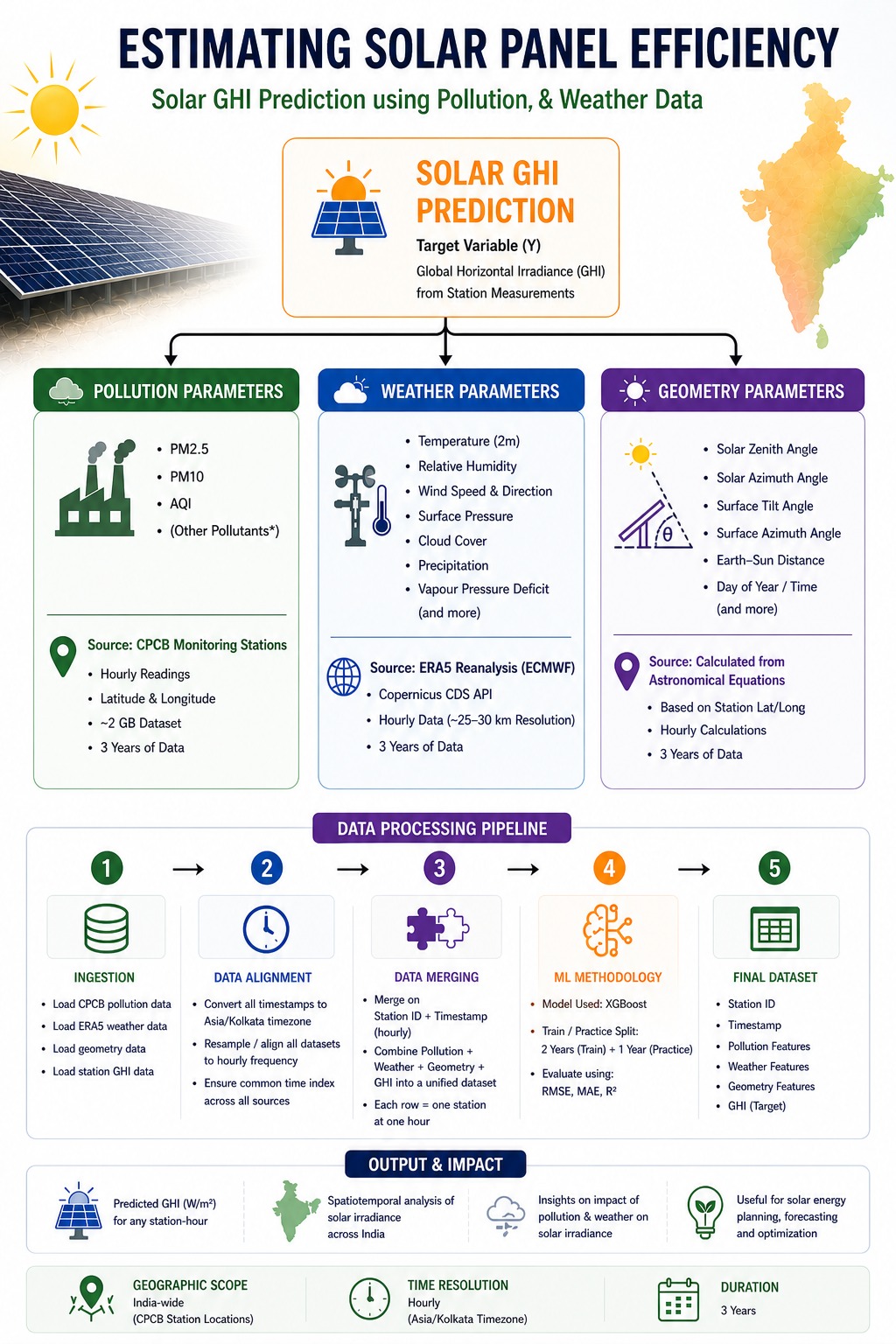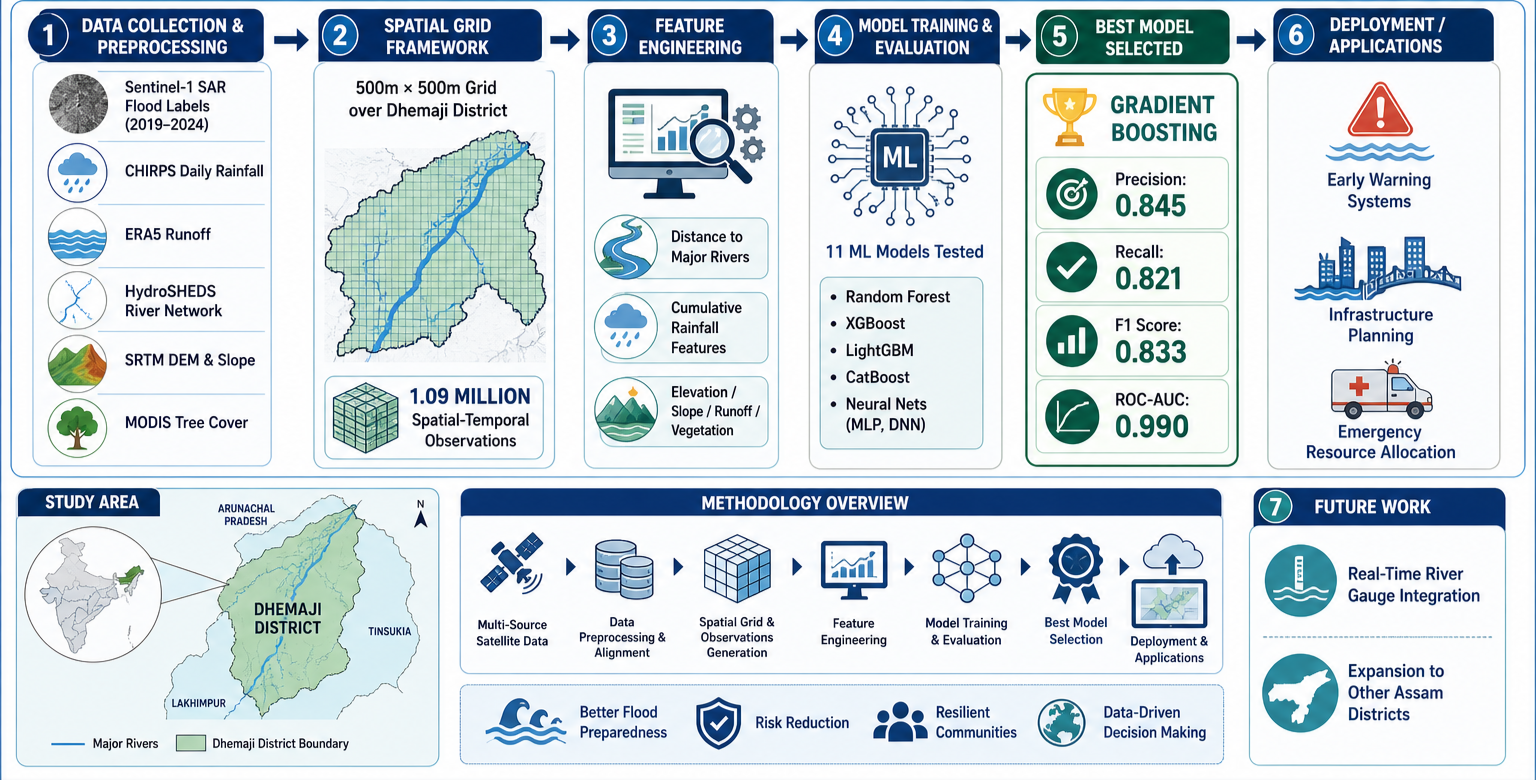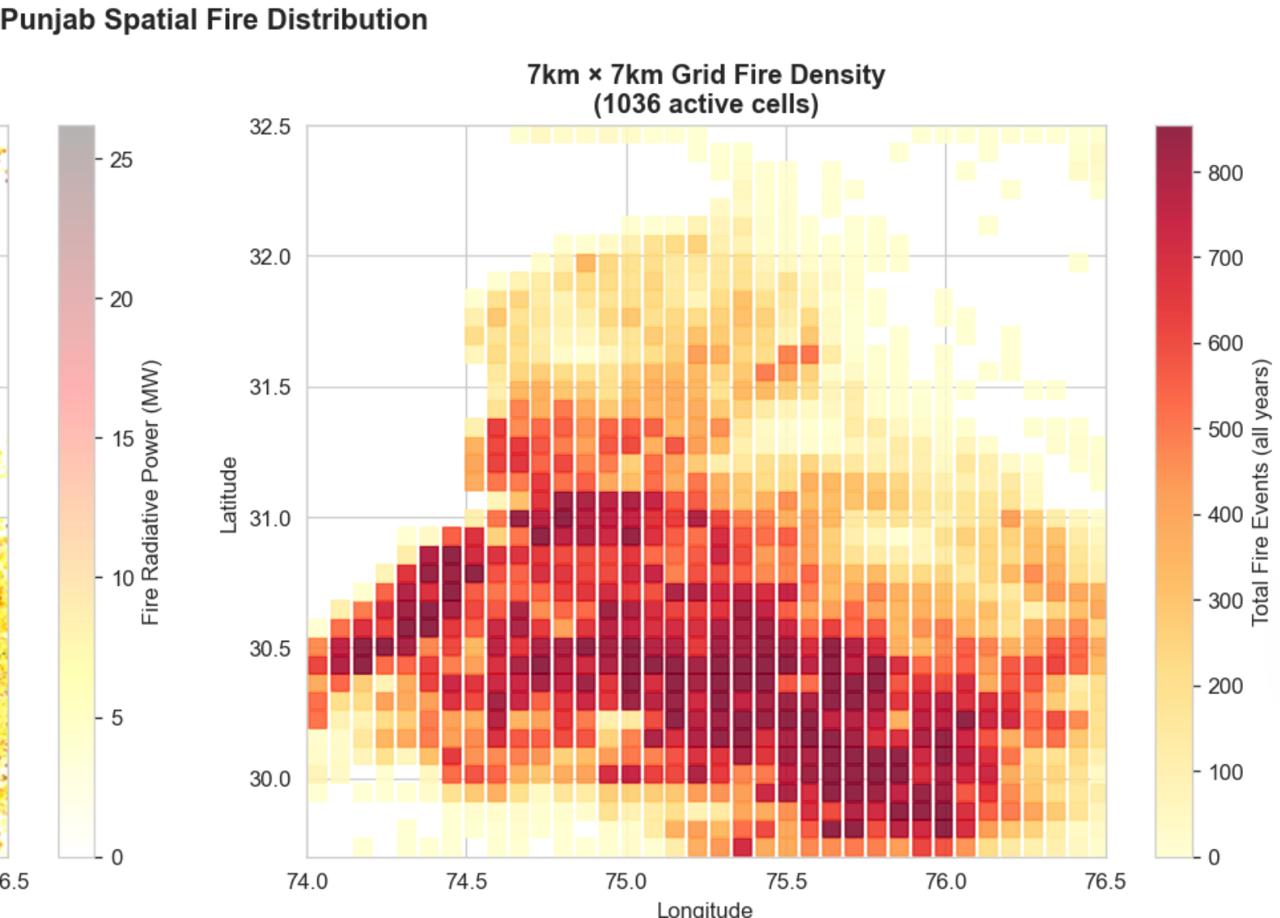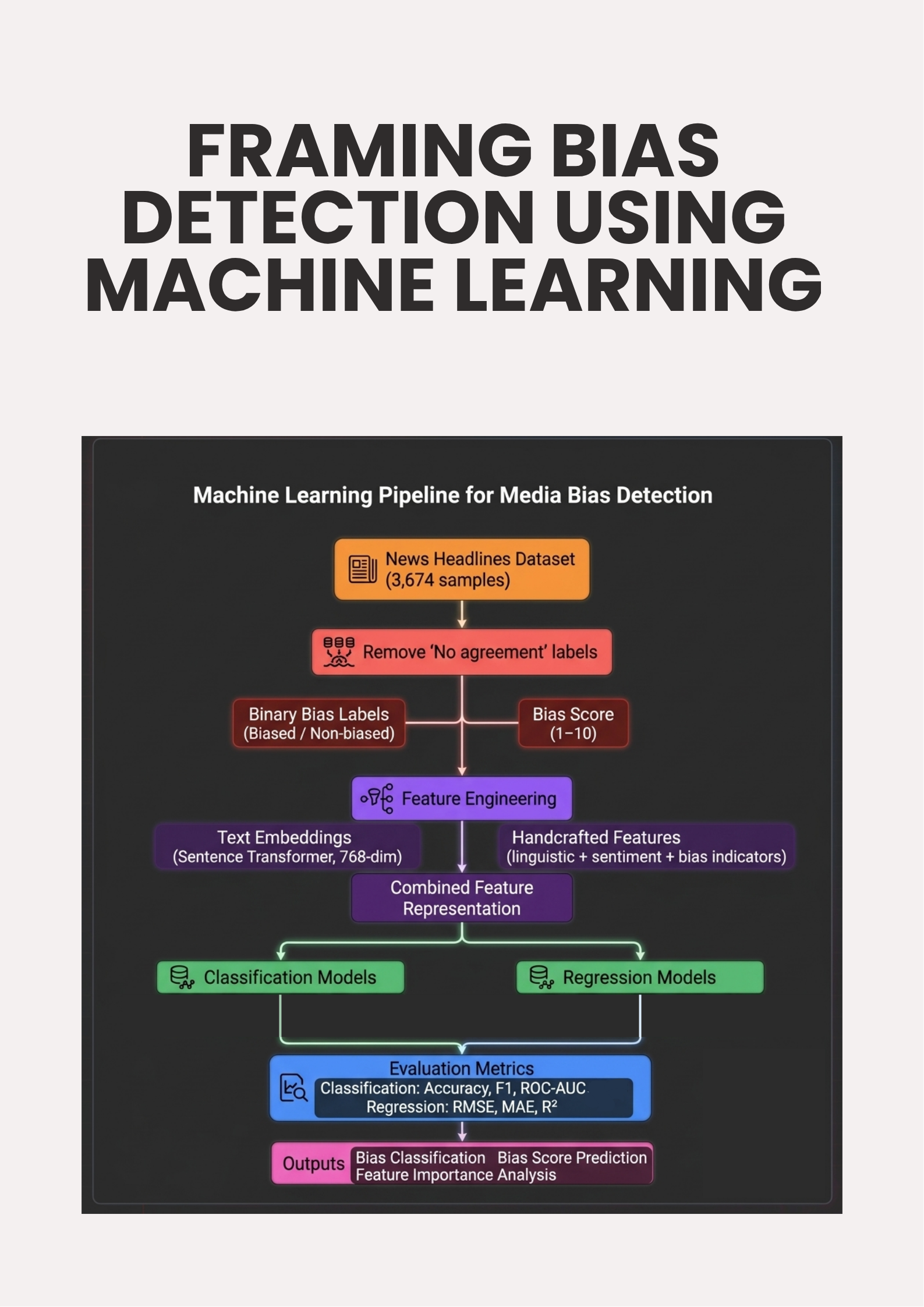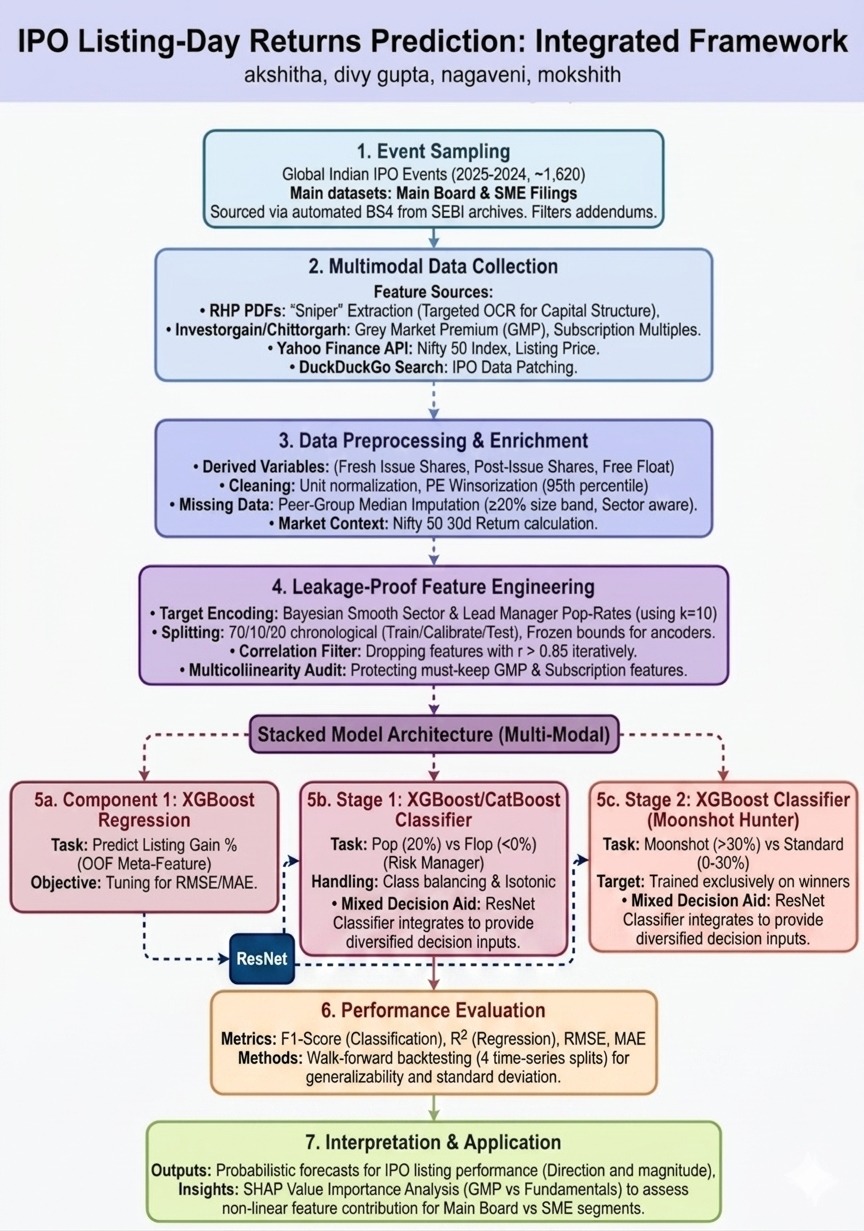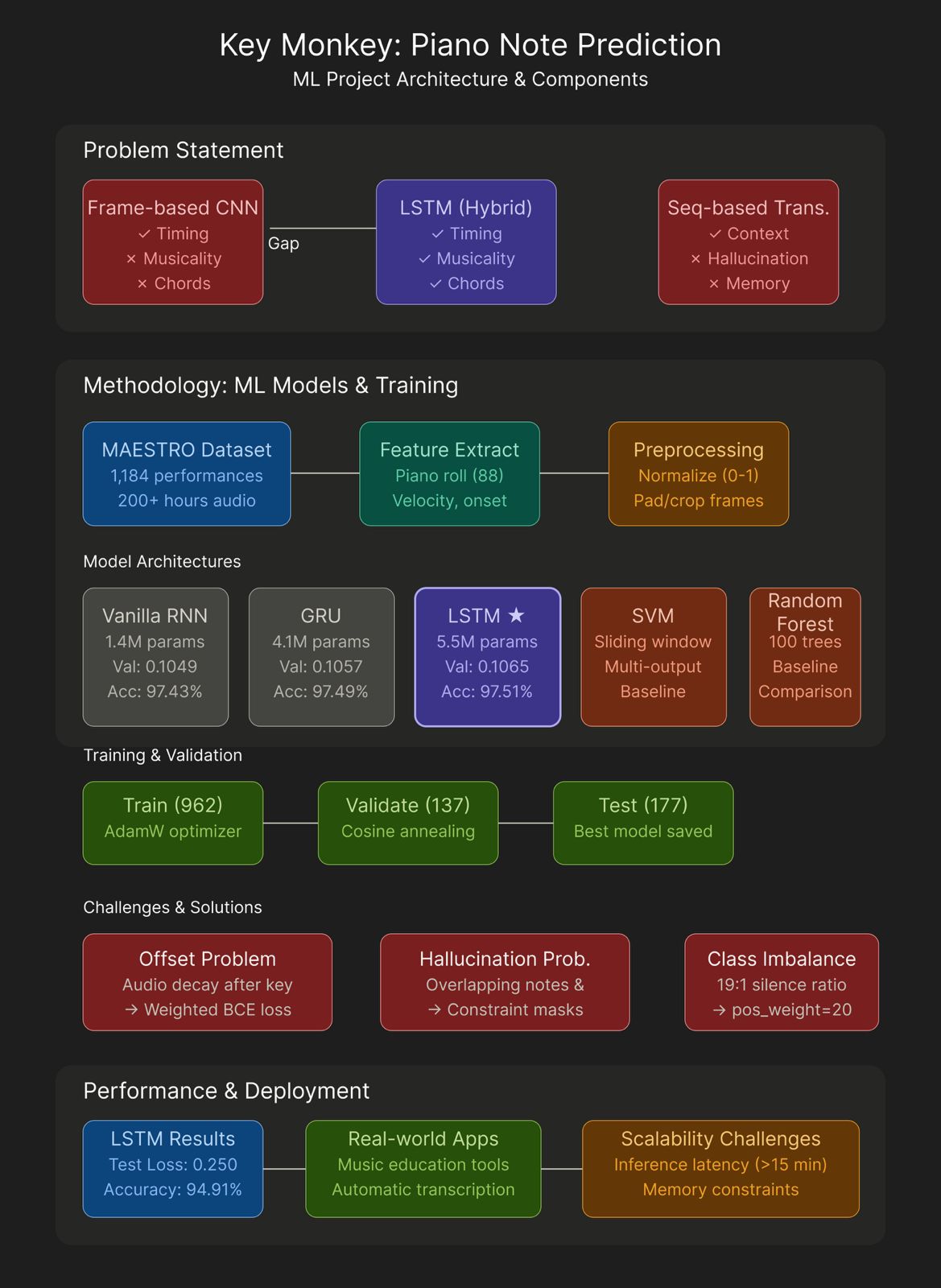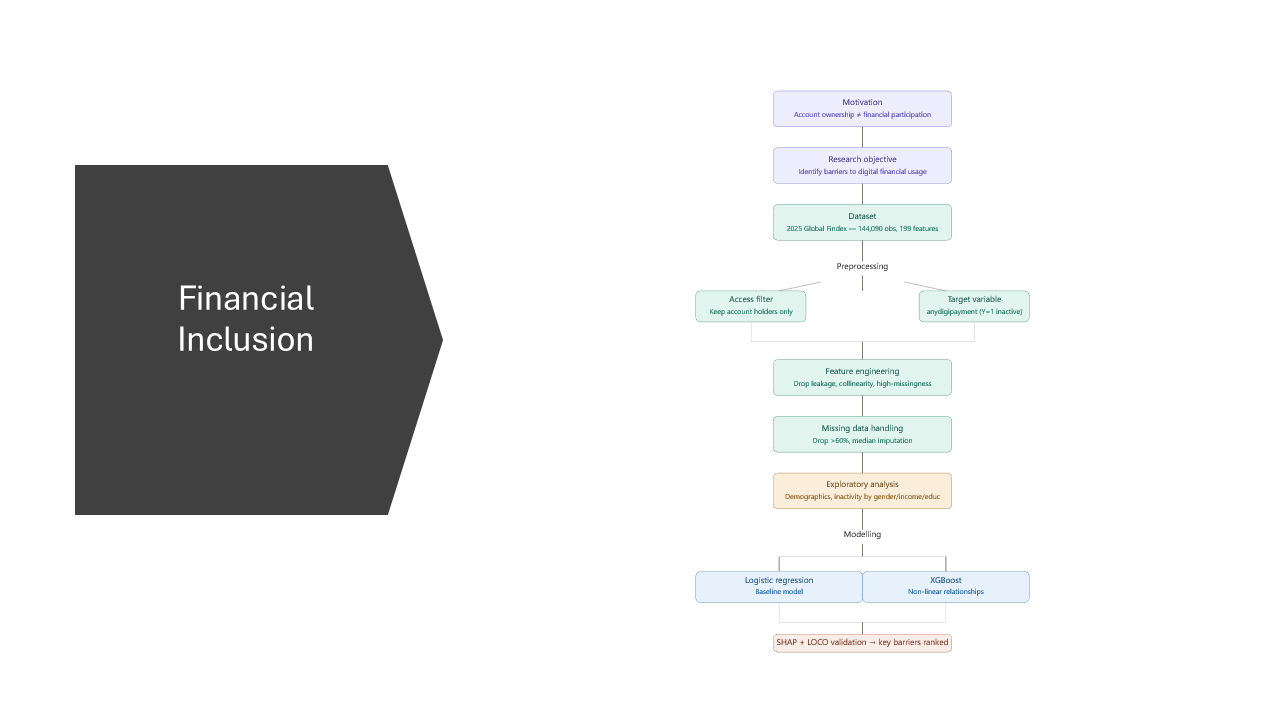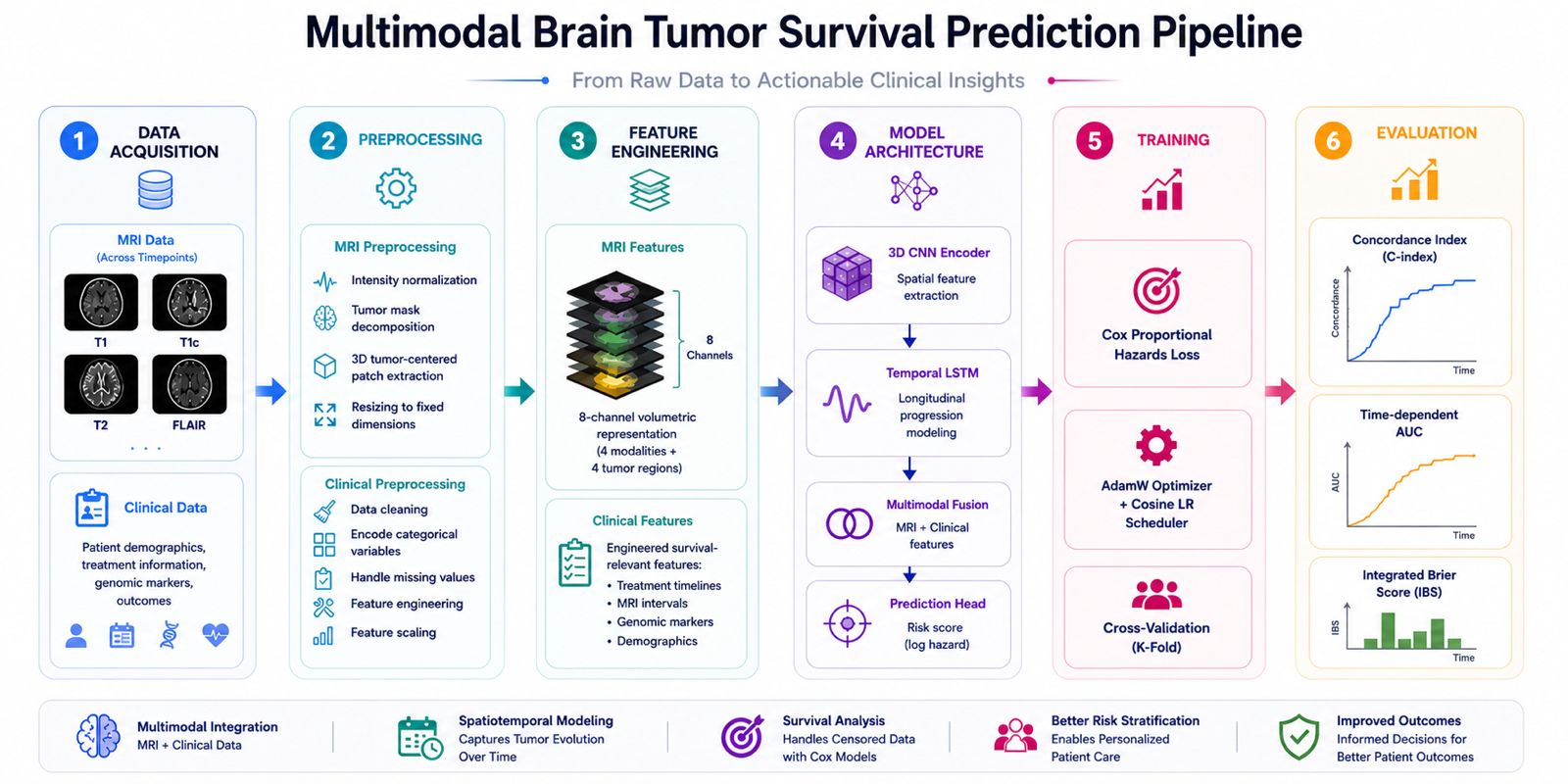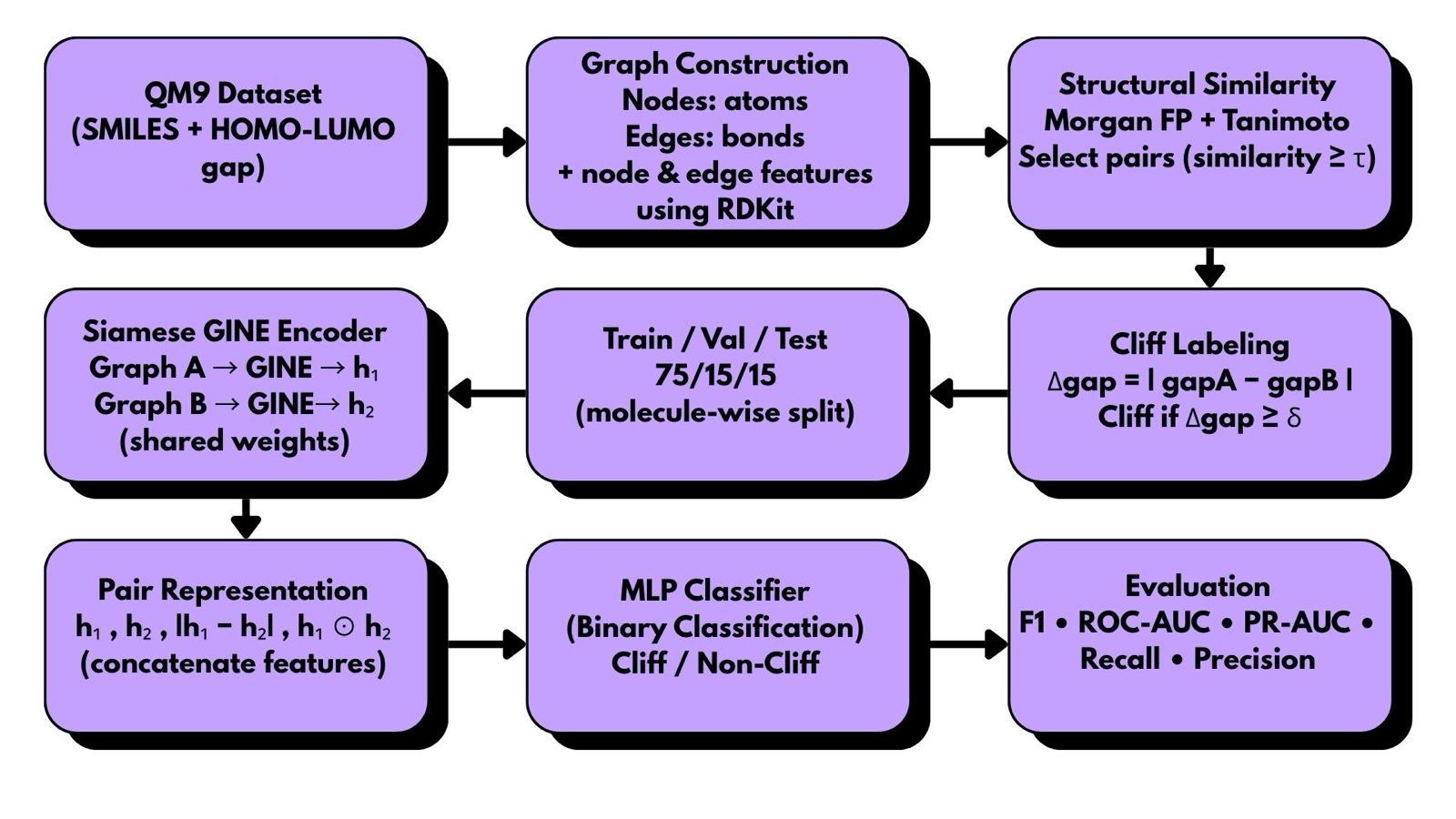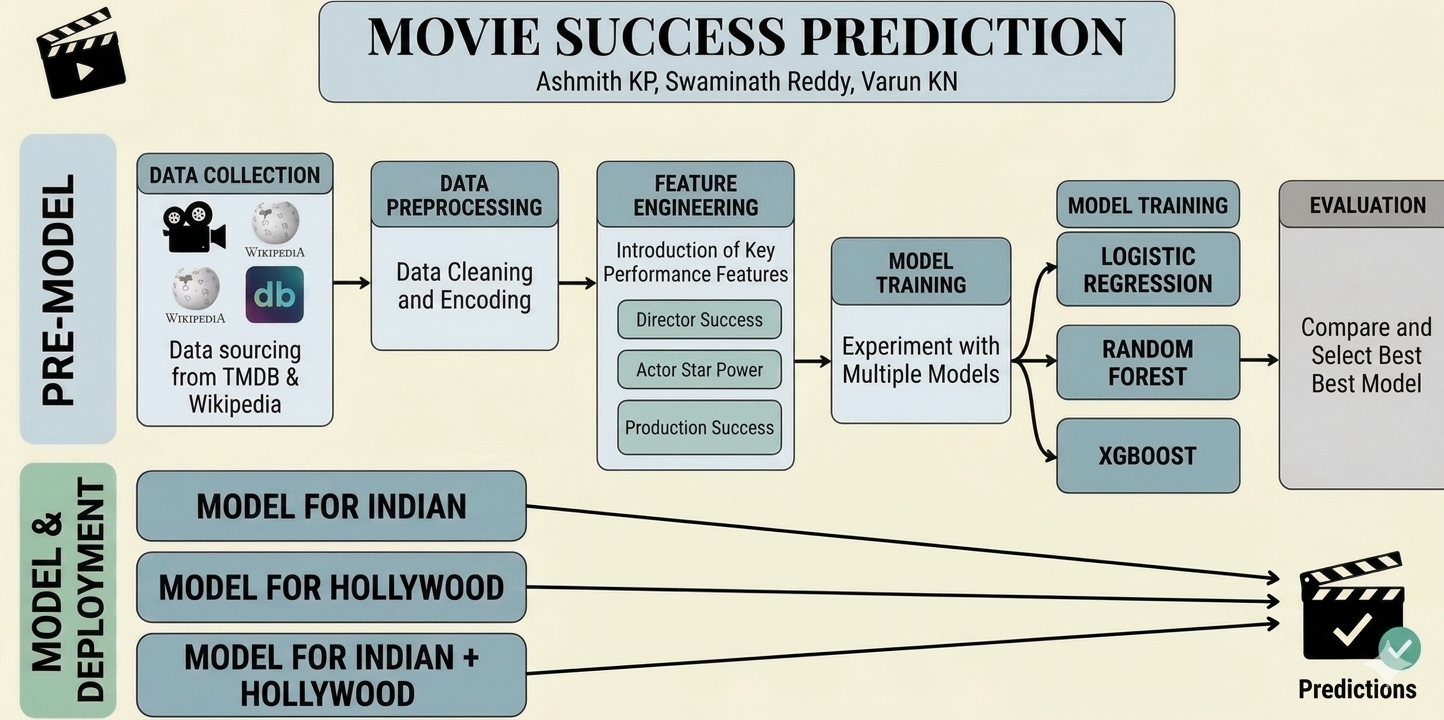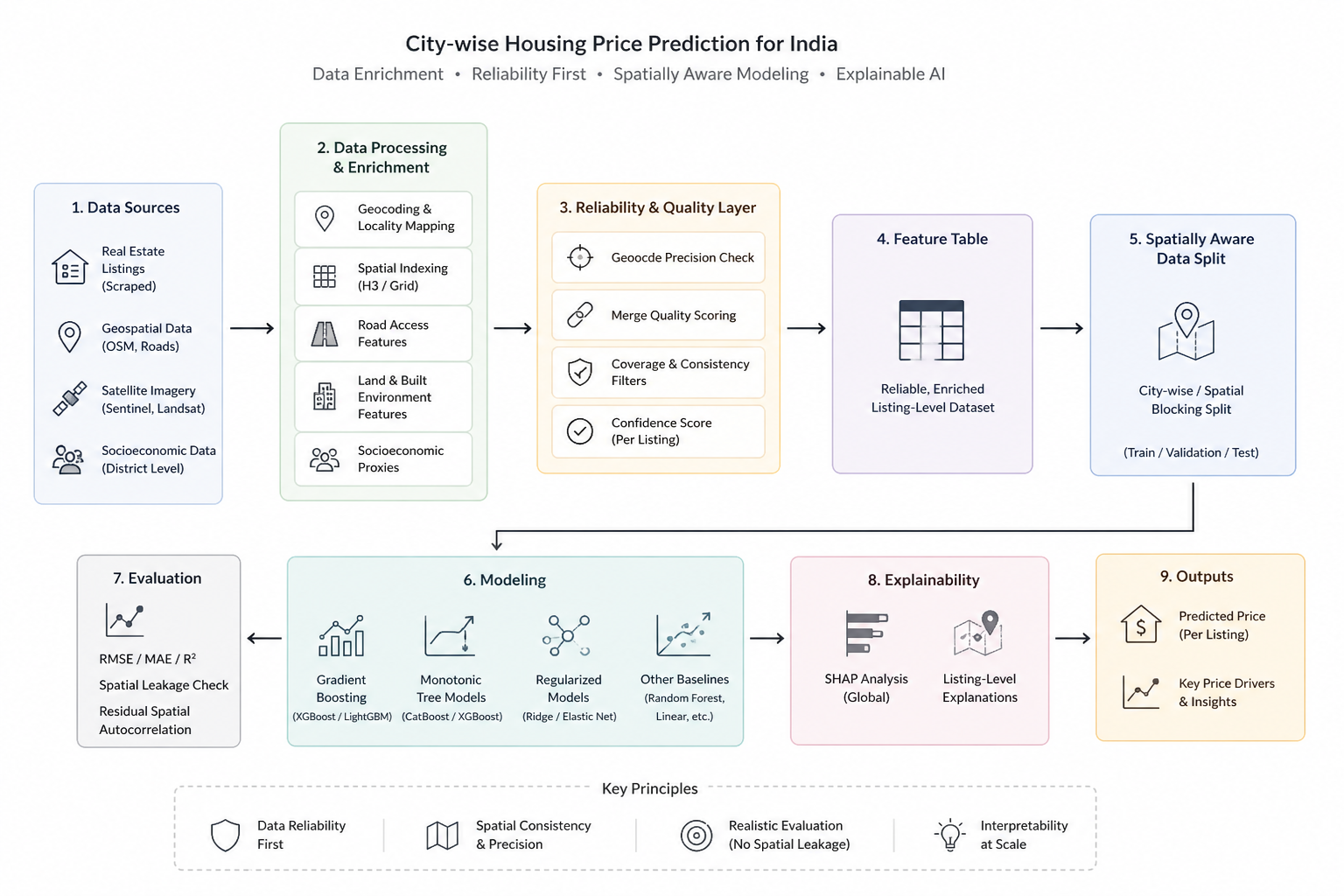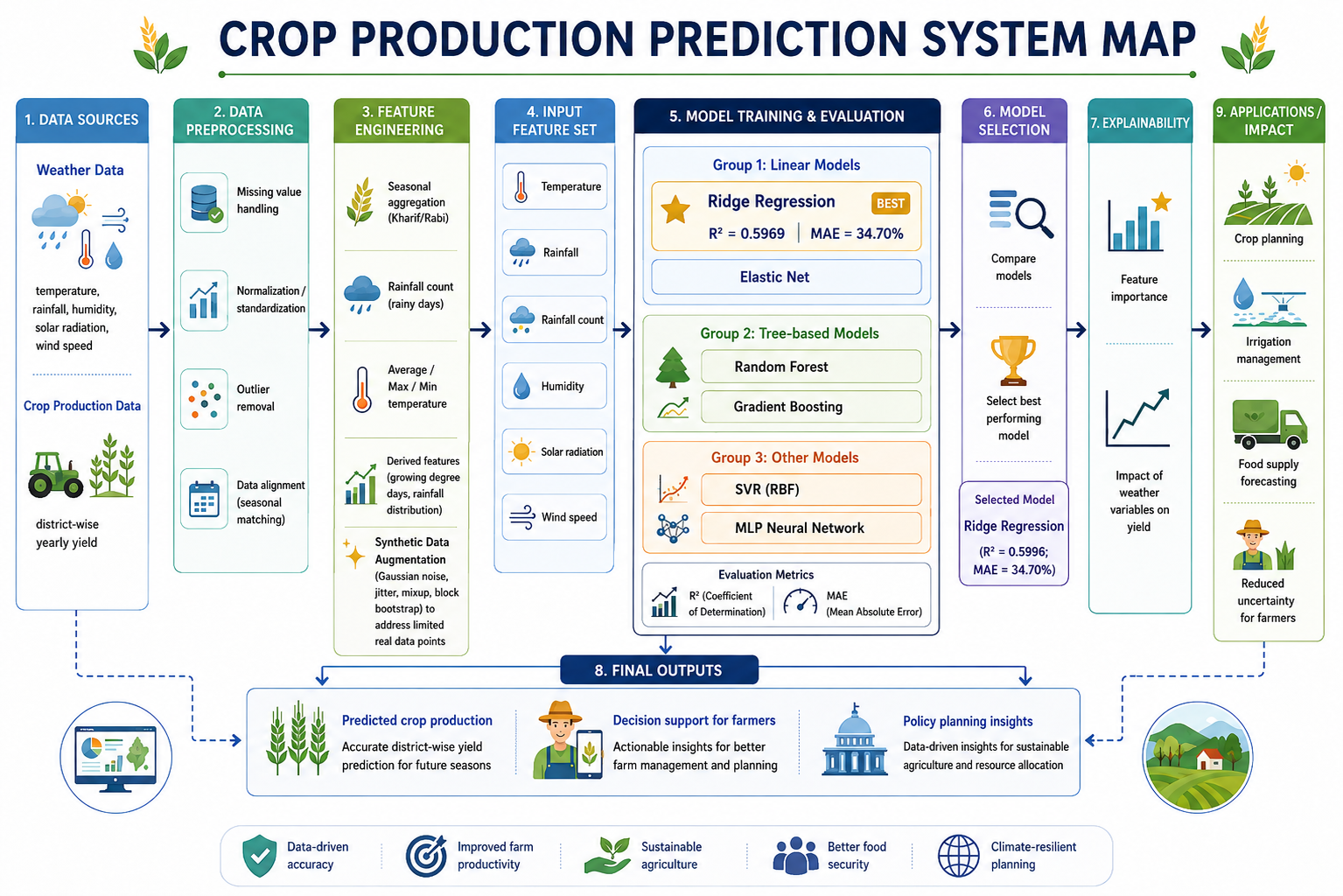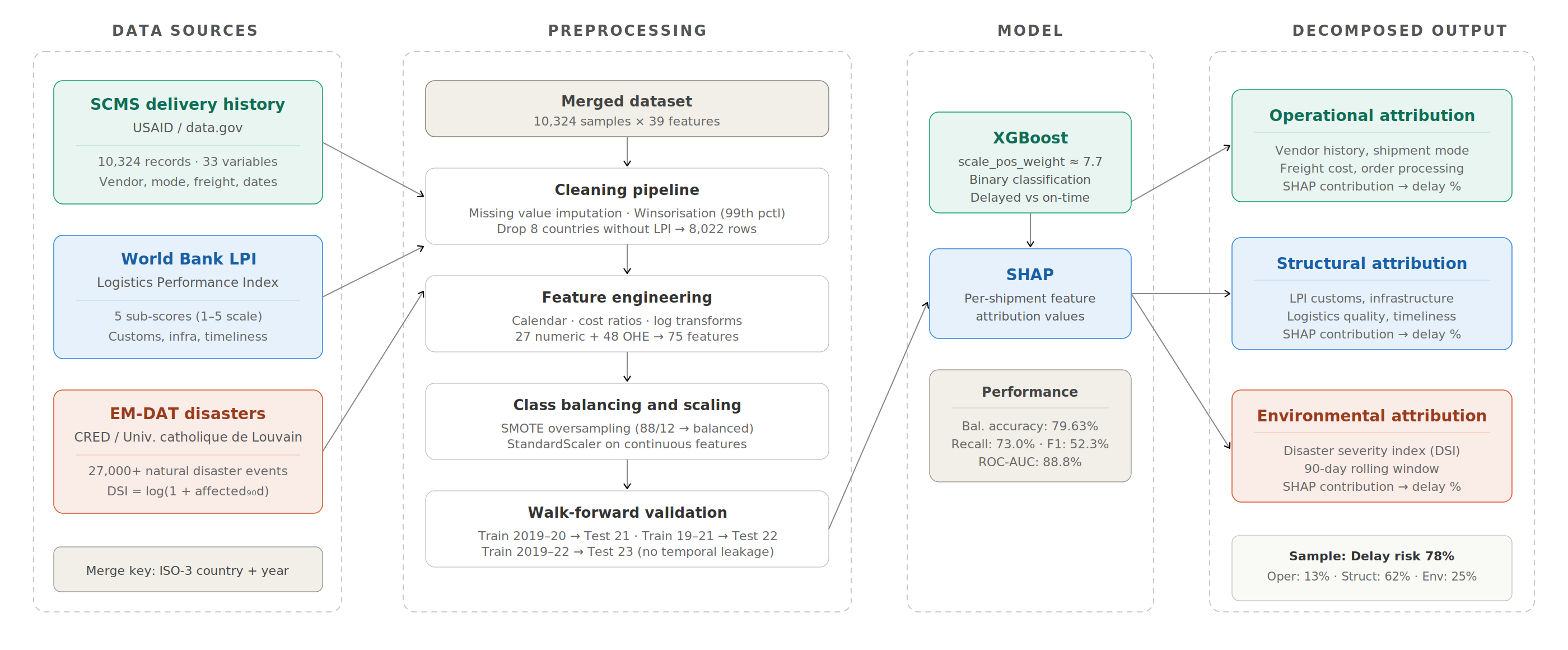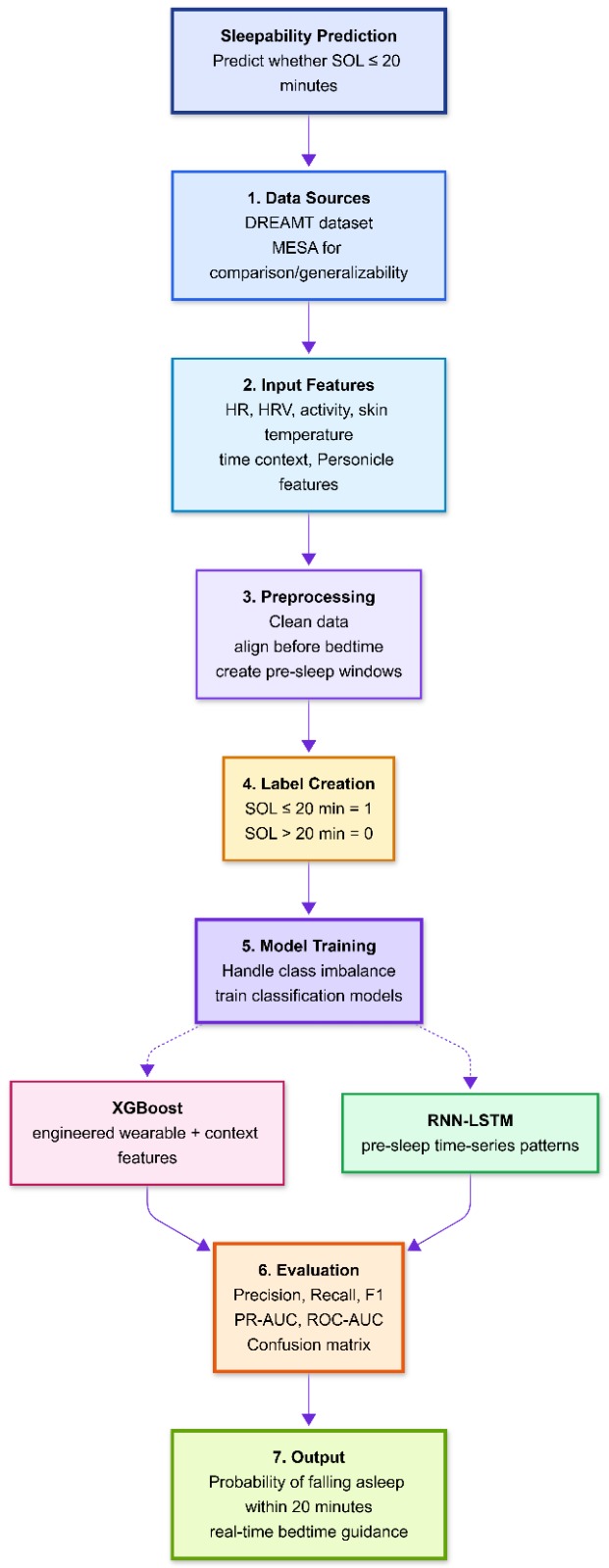
Flight delays cost the aviation industry billions annually, yet existing predictive models focus only on whether a flight will be delayed — not whether it can recover. This project addresses that gap by building a system that predicts, before departure, both the likelihood and magnitude of in-air delay recovery for commercial flights.
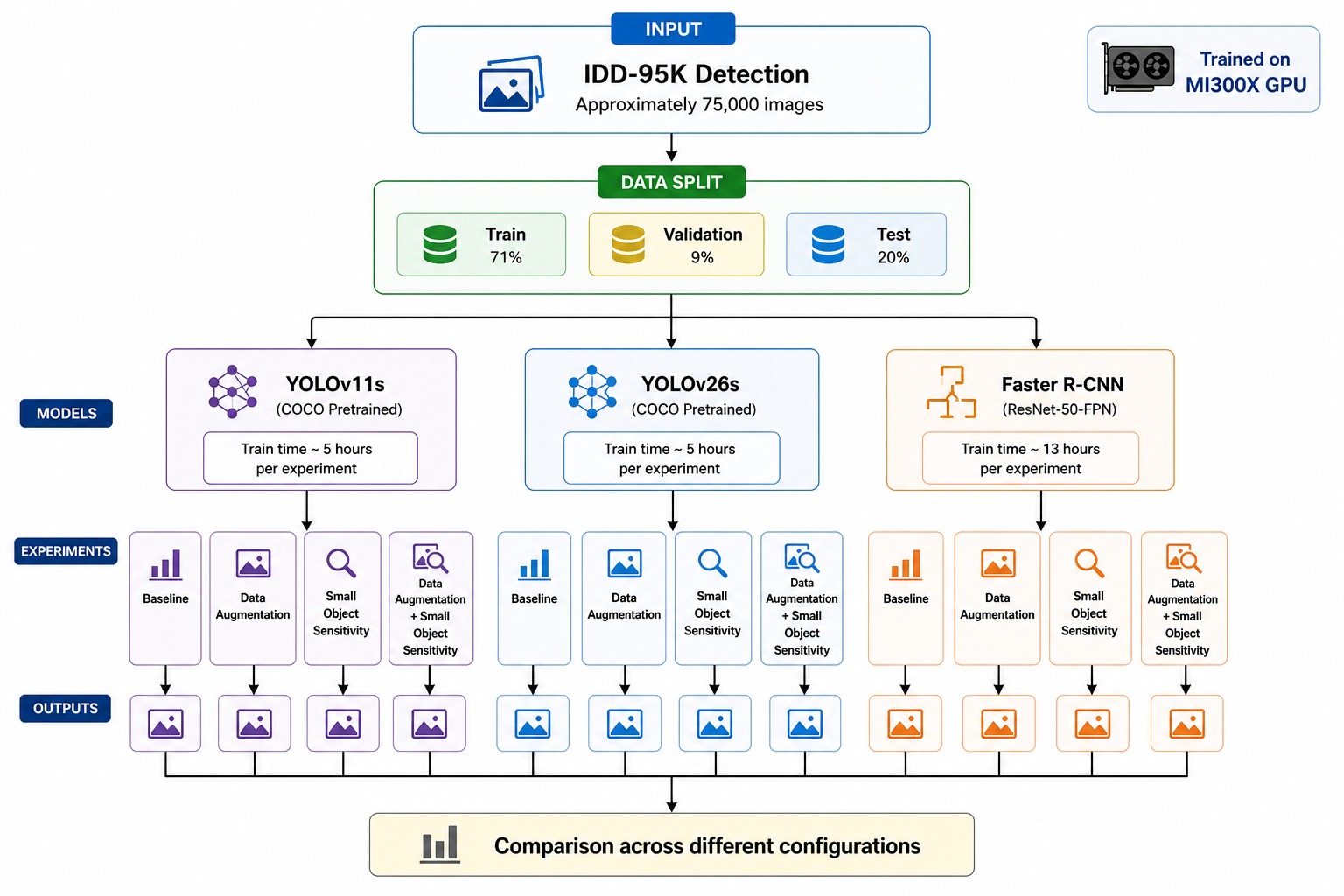
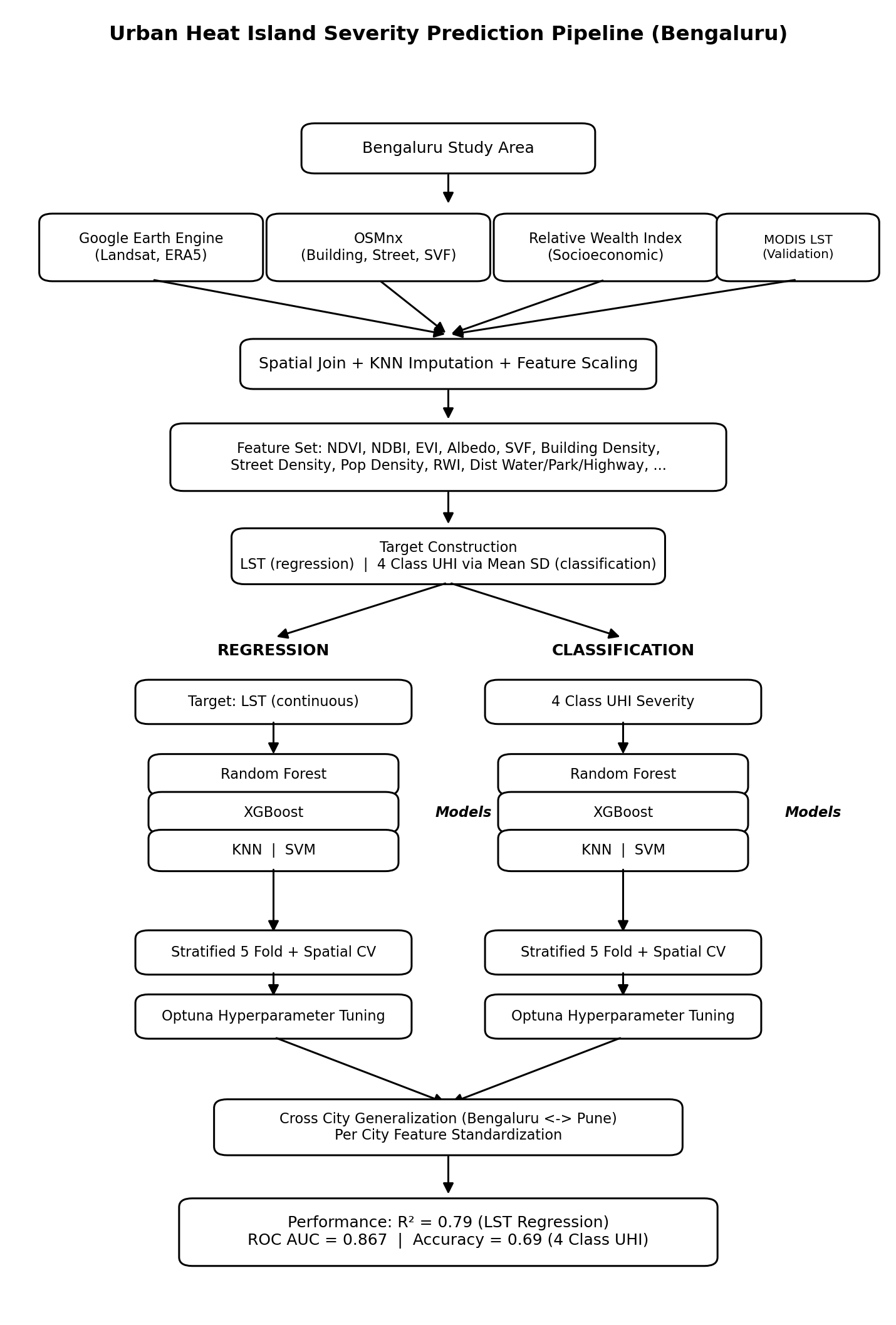
Using the Aeolus 2024 dataset (6.28M flights, 22 features), we engineered a physics-grounded feature set — including Padding Ratio, Available Buffer, and cyclical departure time encodings — applied strict temporal data splitting to eliminate leakage, and used target encoding to efficiently handle hundreds of airports without dimensionality explosion.
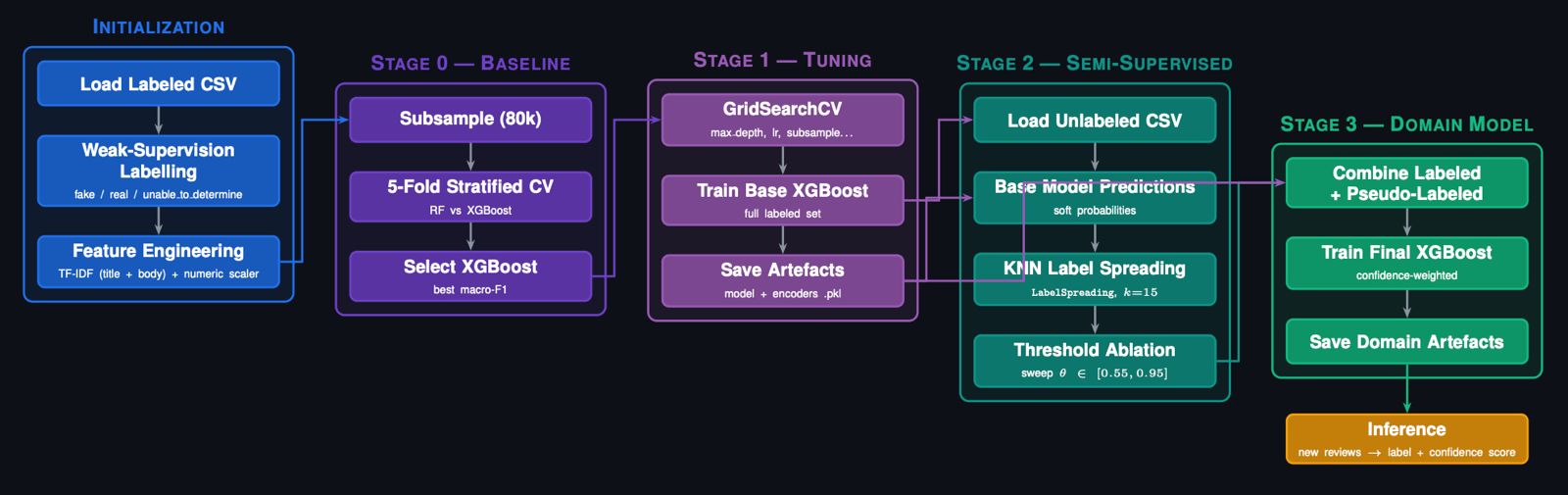
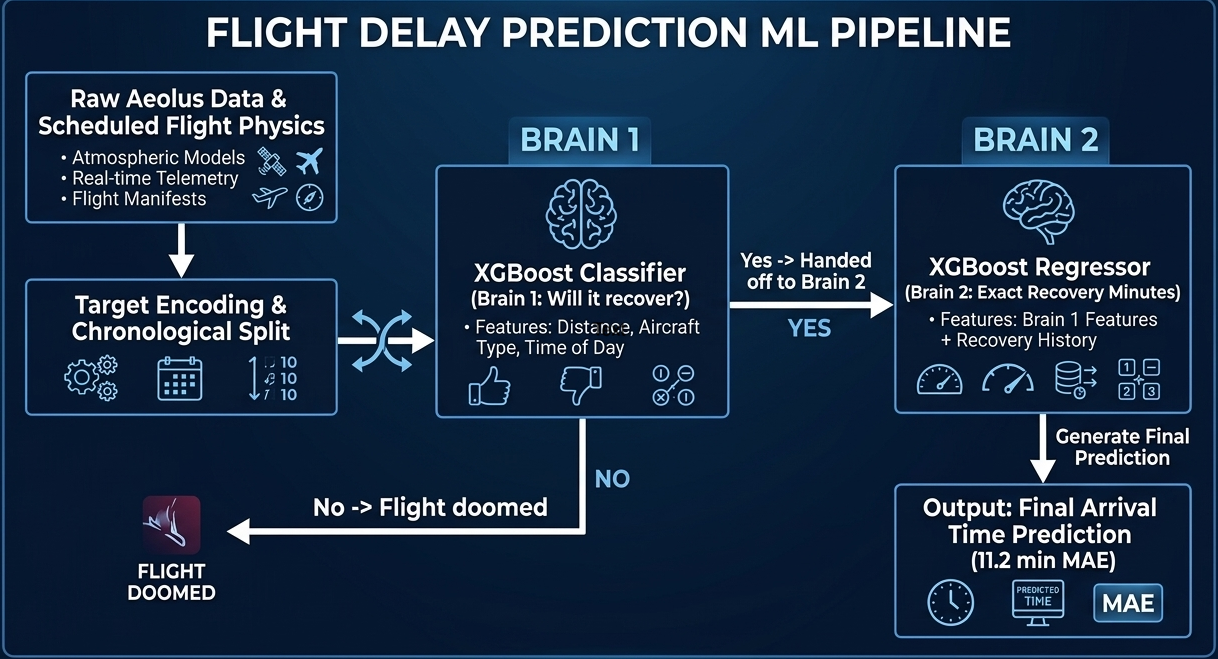
Our architecture, a sequential Two-Brains XGBoost pipeline, separates the problem into two stages: a Gatekeeper Classifier that screens flights incapable of recovery, and a Predictor Regressor that estimates exact recovery minutes for viable flights. Stage 1 Precision (73.58%) is the architectural bottleneck — low precision floods the regressor with unrecoverable flights, corrupting its training gradient. Stage 2 achieves a Test MAE of 10.88 minutes, improving to 5.41 minutes after Optuna-based Bayesian hyperparameter optimization. SHAP values provide full prediction explainability, making the system interpretable for aviation stakeholders.